
 Watch Now !!
Watch Now !! Watch the Video -
Watch the Video -  Watch the Video -
Watch the Video -  Watch the Video -
Watch the Video -  Watch the Video -
Watch the Video - 






26
JunDSA Interview Questions and Answers (Freshers to Experienced)
23 Sep 2025
Question
32.5K Views
41 min read

Learn with an interactive course and practical hands-on labs
Free DSA Online Course with Certification
Data Structures Interview Questions and Answers are crucial for anyone preparing for software development, data science, or technical job roles. Data structures help in organizing and storing data efficiently, making them a fundamental concept in programming. To excel in a data structures interview, you need a strong grasp of arrays, linked lists, stacks, queues, trees, graphs, hash tables, and algorithms.
In this Data Structures tutorial, we provide a list of commonly asked Data Structures Interview Questions and Answers to help you prepare for top tech companies. Whether you're a beginner or an experienced developer, this guide will boost your confidence and sharpen your problem-solving skills for your next interview. DSA skills can boost your tech salary by 25% in 2025. Enroll in our Free DSA Course with Certificate today!
Data Structure Interview Questions for Freshers
Data structures are essential for organizing and managing data efficiently. Here are some common interview questions for freshers to help you prepare.
Q1. What is a Data Structure?
A data structure is a method of organizing and storing data in a computer to enable efficient use. It is a key concept in computer science, offering a framework for data management and manipulation. Various data structures are designed for specific tasks, and selecting the appropriate one can greatly influence a program's performance. Data structures include concepts like arrays, queues, stacks, linked lists, and more.
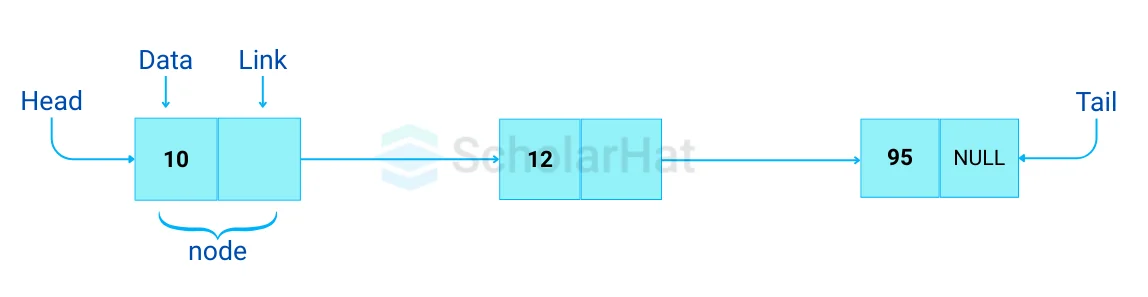
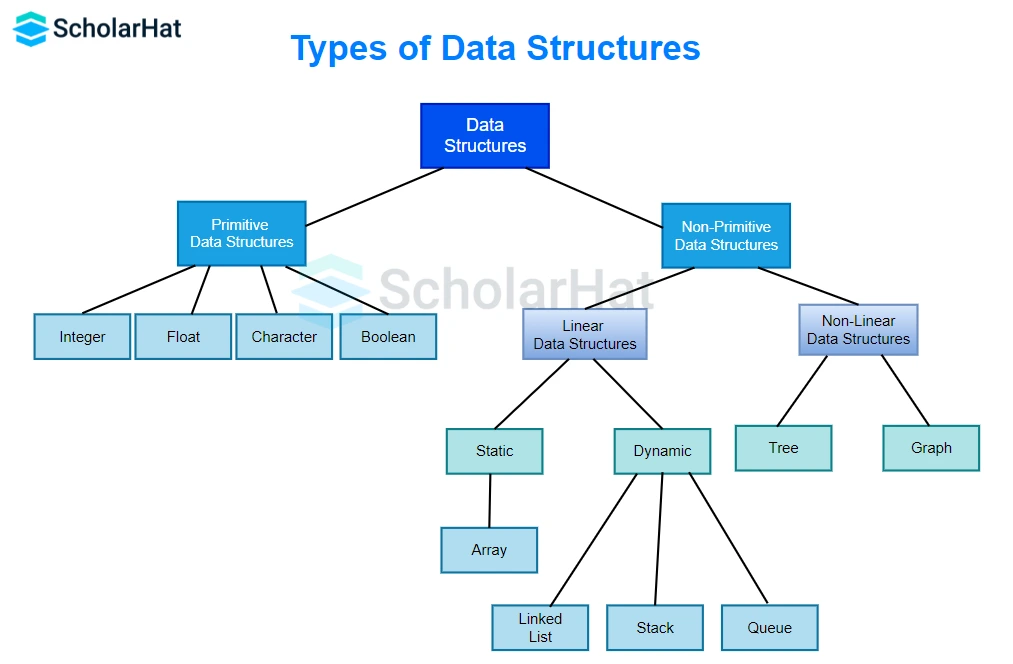
Q2. Can you describe the different types of Data Structures?
There are two main types of Data Structures:
- Linear Data Structure: If every element in a data structure is placed in a sequential order, the structure is referred to as linear. All elements in linear data structures have predecessors and successors, with the exception of the beginning and last elements, which are stored in a non-hierarchical manner.
- Non-linear Data Structures: Each item or element in a nonlinear data structure is related to two or more other items in a nonlinear arrangement; it does not form a sequence. The arrangement of the data elements does not have a sequential structure.
| Read More: Types of Data Structures |
|
Q3. What are some popular Data Structure applications?
Here are a few real-time data structure applications:- Decision Making
- Genetics
- Image Processing
- Blockchain
- Numerical and Statistical Analysis
- Compiler Design
- Database Design and many more
Q4. Describe the distinction between storage and file structures.
The memory area accessed makes a difference. A file structure indicates a storage structure in auxiliary memory, while a storage structure refers to a data structure in the computer system's memory.
Q5. Which data structures are often used in hierarchical data models, network data models, and relational database management systems?
- RDBMS makes use of the Array data structure
- The network data model makes use of a Graph in the data structure
- The hierarchical data model makes use of Trees in data structure
Q6. Which type of data structure is typically used when recursion is carried out?
The stack data structure is used in recursion in data structures because it is last-in in first-out. To save the iteration variables at each function call, the operating system keeps the stack maintained.
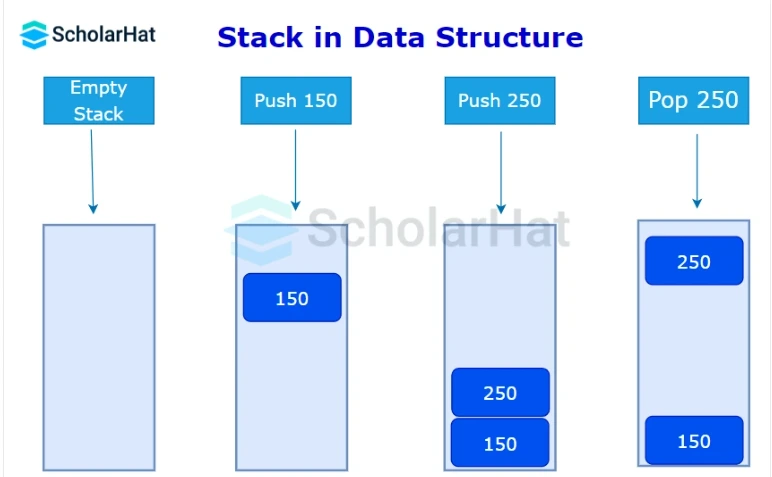
Q7. Describe a stack and explain how it operates.
A stack in the data structure is an ordered list where changes can only be made at one end, referred to as the top. The data structure is recursive and contains a pointer to its uppermost element. The Last-In-First-Out (LIFO) list, which denotes that the element added to the stack first will be removed last, is another name for the stack.
Q8. What are some examples of applications that make use of the Stack Data Structure?
Here are some of examples of Stack data structure:
- Prefix, postfix, & infix expression evaluation, expression, or conversion
- Syntax parsing
- Reversing a string
- Parenthesis checking
- Backtracking
- Memory Management
- Calling and returning a function
Q9. What kinds of operations are possible on a Stack?
There are three basic operations that can executed by stack in data structure:
- PUSH: A new element is inserted into the stack via the push action. The top of the stack is occupied by the new feature.
- POP: The top member of the stack is removed using the pop operation.
- PEEK: A peek action does not remove the top element from the stack; instead, it returns its value.
Q10. Describe a stack overflow condition and explain how it happens.
When the stack data structure reaches its maximum size (Maxsize) and is unable to hold more components, a data structure's stack overflow condition occurs. This usually occurs as a result of:- Adding more items on the stack than it can hold at once, results in the "top" index reaching Maxsize - 1.
- Failing to remove components from the stack to make space for new ones, causes an overflow when you try to add more.
Q11. Is it possible to distinguish between a stack's POP and PUSH operations?
The ways in which data is stacked and retrieved are defined by the Stack's PUSH and POP procedures.
- PUSH: The data being "inserted" onto the stack is indicated by the PUSH command.
- POP: POP describes how to retrieve data. It denotes the removal of data from the stack.
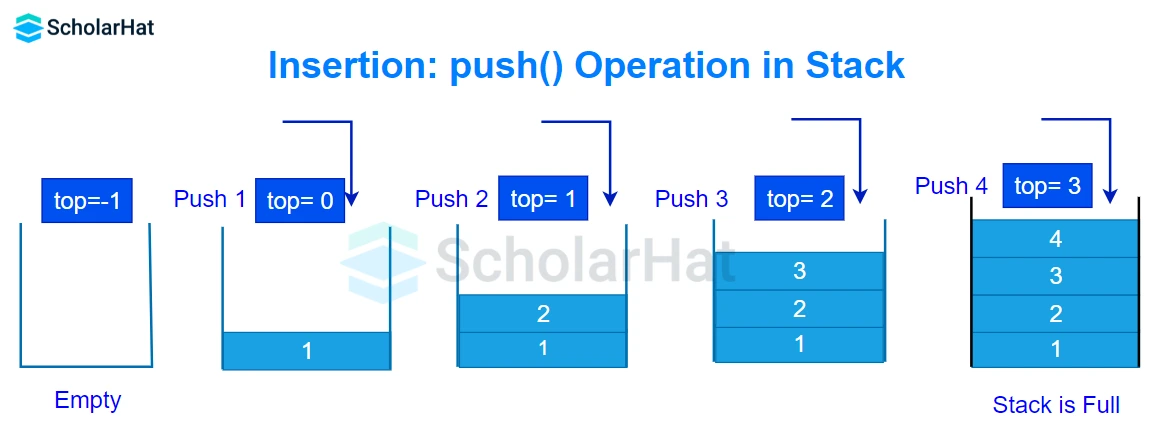
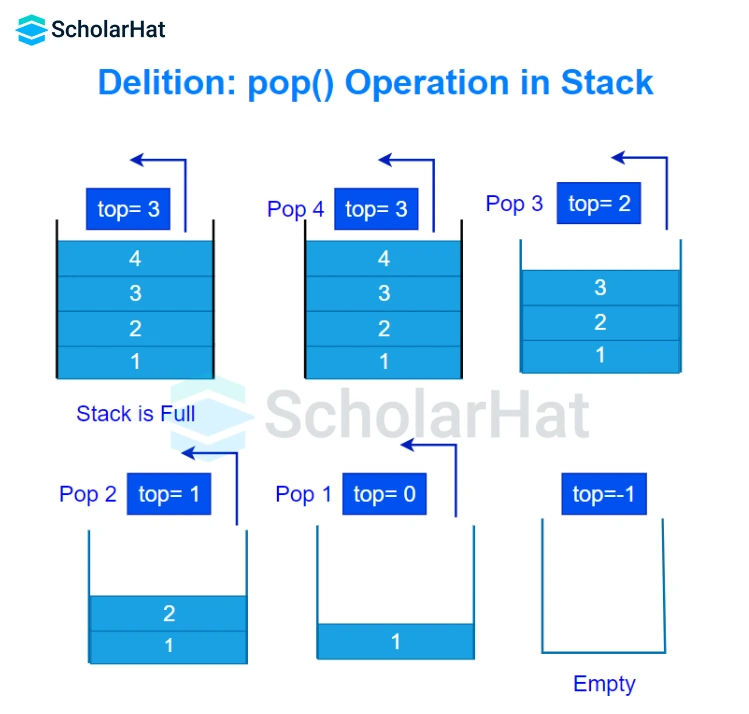
Q12. Explain the process of adding and removing an element from a stack.
Push:
- To enable it to refer to the next memory allocation, increase the variable top.
- Copy the item to the top of the array at the array index value.
- Proceed step by step until the stack overflows.
 Pop:
Pop:
- Put the element at the top into a different variable.
- Lower the top element's value.
- Return the element at the top.
Q13. What is an expression with a postfix?
A postfix expression is one where the operators come after the operands. The primary advantage of this format is that it eliminates the need to take operator precedence into account or group sub-expressions in parenthesis. In postfix notation, the expression "a + b" will be written as "ab+".Q14. Give the expression's postfix form: (A + B) * (C - D).
The expression (A + B) * (C - D) has the following postfix form, which is also referred to as Reverse Polish Notation, or RPN: AB+CD-*Q15. When evaluating arithmetic expressions utilizing the prefix and postfix forms, which notations are used?
When evaluating arithmetic expressions using prefix and postfix forms, the following notations are often used:
- Prefix Notation (or Polish Notation): Polish notation, often known as prefix notation, arranges the operators before the operands.
- Postfix Notation (or Reverse Polish Notation, RPN): Reverse Polish Notation, or RPN, often known as postfix notation, arranges the operator after the operands.
Q16. What is an array, and how are elements in a one-dimensional array referenced?
An array in data structure is a grouping of related sorts of data elements kept in contiguous memory regions. It is the most basic data structure, where each data element has an index number that may be used to access it at random. An indexed loop with a counter that runs from 0 to the array size minus one can be used to accomplish this. This way, you may use the loop counter as the array subscript to refer to every element in order.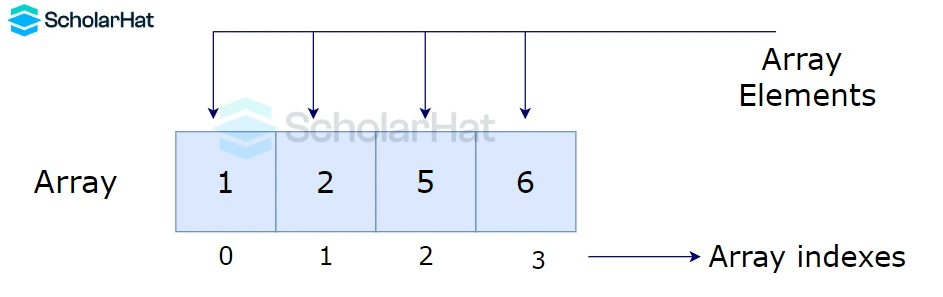
Read More: |
Q17. Explain the concept of a Multi-Dimensional Array and how its Components are kept in Memory.
An array of arrays where data is collected and organized into rows and columns is known as a multidimensional array. To develop a data structure that looks like a relational database, 2D arrays are created. It makes it simple to store a large amount of data at once that may be transferred to numerous functions as needed.
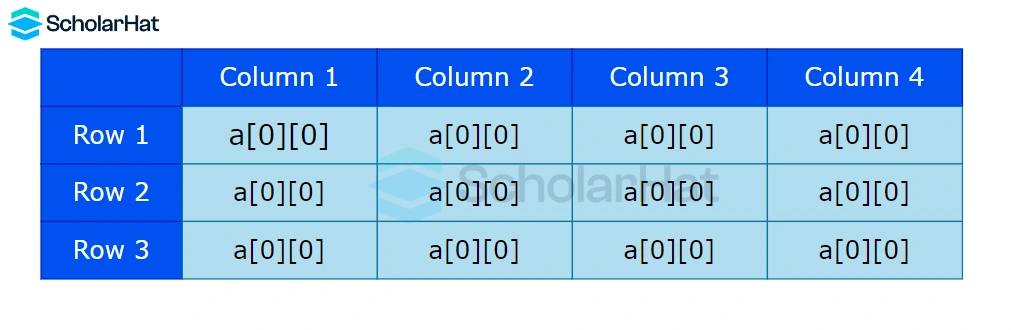
Q18. How can one determine the address of a randomly selected element in a 2D array given its base address?
- Row-Major Order: The address of an element a[i][j] of an array stored in row-major order is determined as follows if the array is specified as a[m][n], where m is the number of rows and n is the number of columns. Address(a[i][j]) = B. A. + (i * n + j) * size
- Column-Major Order: The address of an element in an array stored in column-major order, a[i][j], is determined as follows if the array is declared as a[m][n], where m is the number of rows and n is the number of columns. Address(a[i][j]) = ((j*m)+i)*Size + BA.
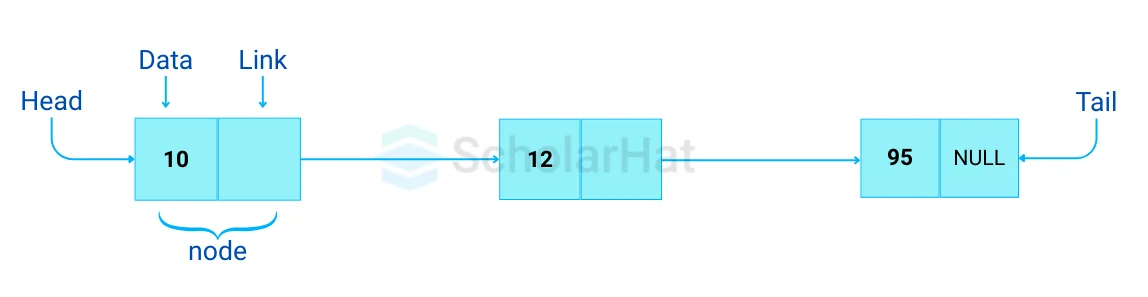
Q19. Describe the Linked List data structure.
A sequence of linked nodes (or items) connected by links (or pathways) can be created as a linked list data structure. The next node in the series is indicated by each link, which represents an entry into the linked list. The order in which nodes are generated dictates the order in which they are added to the list.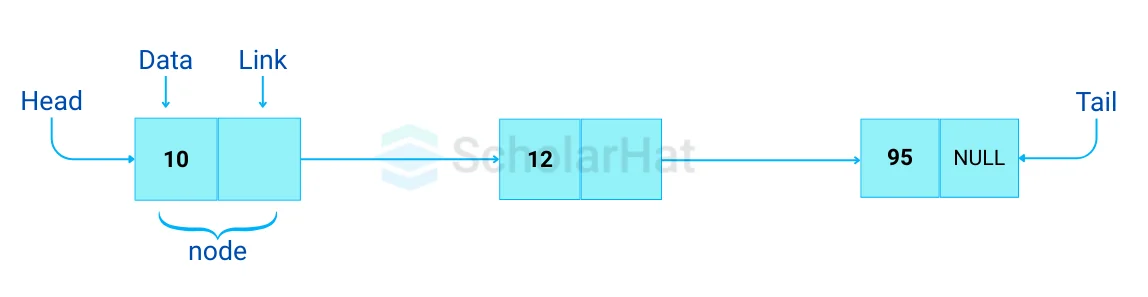
Q20. Are Linked Lists considered linear or non-linear data structures?
Linked lists can be classified as linear or non-linear data structures based on the purpose for which they are utilized. Regarded as a linear data structure, it is used for access techniques. It is regarded as a non-linear data structure when utilized for data storage.
DSA Interview Questions for Intermediates
If you have a basic understanding of data structures and algorithms, these intermediate-level questions will help you test and improve your problem-solving skills.
Q21. What are the advantages of linked lists over arrays?
Advantages of linked lists are as follows:
- A linked list's size can be increased at runtime, whereas an array's size cannot be changed.
- Nodes can be kept anywhere in the memory that is connected by links; the List does not have to be continuously present in the main memory if contiguous space is not available.
- While the array is statically kept in the main memory and requires size declaration at compile time, the list is dynamically put there and expands based on program demands.
- While the number of elements in an array is limited by the array's size, the number of elements in a linked list is restricted by the amount of RAM that is available.
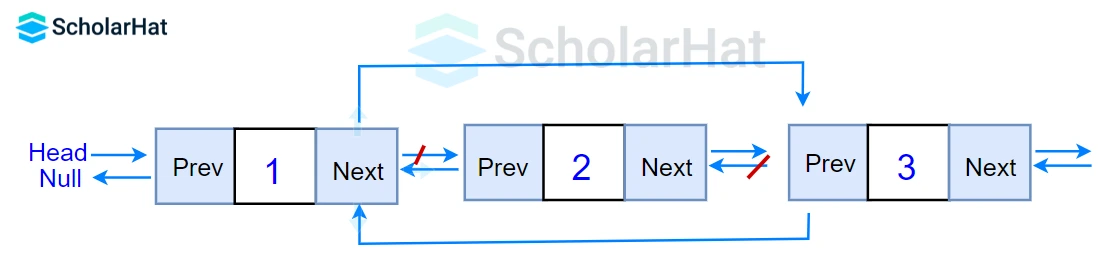
Q22. Define a doubly linked list.
The doubly linked list is a more complex linked list in which each node carries a pointer to the previous and next node in the sequence. A node in a doubly linked list comprises three components: node data, the next pointer, which is a pointer to the node after it in the sequence, and the prior pointer, which is a pointer to the node before it.
Q23. Describe the various kinds of array data structures in detail.
There are numerous types of arrays in data structure, including:
- One-dimensional array: A single index value is used to access the elements of a one-dimensional array, which are kept at consecutive memory regions. All of the components are arranged in a series within this linear data structure.
- Two-dimensional array: A tabular array with rows and columns that holds data is called a two-dimensional array. M rows and N columns are grouped into N rows and columns to generate an M × N two-dimensional array.
- Three-dimensional array: A three-dimensional array is a grid that includes rows, columns, and depth as a third dimension. It consists of a cube with three dimensions: depth, rows, and columns. There are three subscripts in the three-dimensional array for each place in a given row, column, and depth. The first index is depth (a dimension or layer), the second is row, and the third is column.
Q24. Which pointer type should be used in C when creating a heterogeneous linked list?
Since the heterogeneous linked list contains a variety of data types, standard pointers cannot be used in this situation. The void pointer is a general pointer type that may store a pointer to any type, so you must use it for this purpose.Q25. Describe the Queue data structure.
An ordered list or linear data structure with elements accessed via the First In First Out (FIFO) method is specified by an abstract data type called a queue in data structure. Only one end, known as REAR, is available for insert operations, and the other end, known as FRONT, is available for deletion actions.
|
Q26. What are some examples of Queue data structure applications?
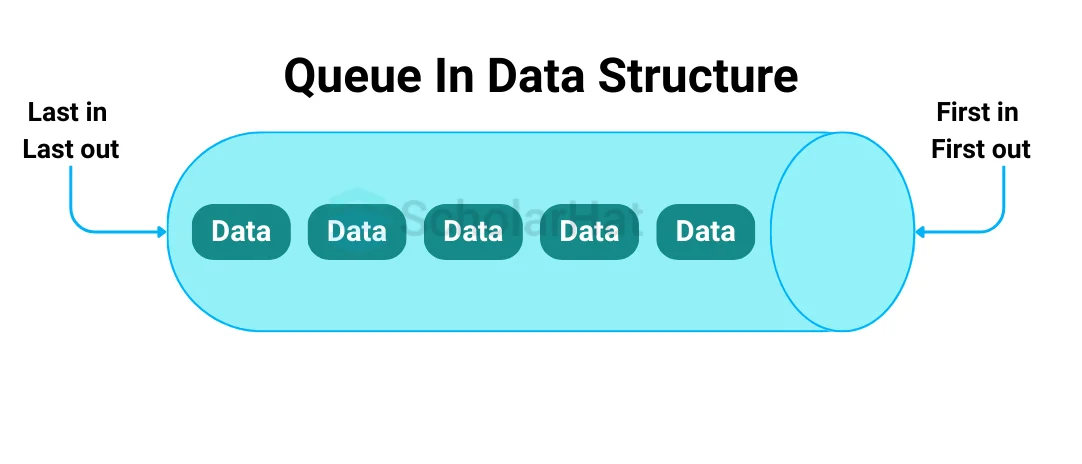
The queue's applications are listed as follows:
- A common usage for queues is as waiting lists for a single shared resource, such as a CPU, disc, or printer.
- Queues are used for asynchronous data transfers, such as file IO, sockets, and pipes, where data is not sent between processes at the same rate.
- Most applications, including CD players and MP3 media players, use queues as buffers.
- In media players, queues are used to manage the playlist and add and remove music from the playlist.
- Operating systems use queues to manage interrupts.
Q27. What are the disadvantages of using an array to build a queue?
- Wastage of Memory: Because elements may only be inserted at the front end and the value of the front may be so high that all of the space before that can never be filled, the array space used to store queue elements can never be reused to store the elements of that queue.
- Array Size: Choosing the appropriate array size is a constant challenge when implementing a queue using an array since there may be circumstances in which we need to expand the queue to accommodate additional elements. If we utilize an array to create the queue in the data structure, this will be nearly hard to do.
Q28. What kinds of situations allow for the insertion of elements into a circular queue?
The kinds of situations that allow for the insertion of elements into a circular queue are as follows
- If (rear + 1)%maxsize = front, the queue is full. Then, overflow happens, making it impossible to perform insertion in the queue.
- If rear != max - 1, the rear is going to be increased to the mod(maxsize), as a new value will be inserted at the rear end of the queue.
- If front != 0 and rear = max - 1, it indicates the queue is not full; therefore, set the value of rear to 0 as well as insert the new element there.
Q29. What is a Double-ended Queue, or Dequeue?
A dequeue, sometimes referred to as a double-ended queue in a data structure, is an ordered collection of components in which additions and deletions can be made at either or both of the ends or front and back.
Q30. What is a queue with a priority?
An abstract data type called a priority queue in a data structure is comparable to a queue in that each element has a priority value. The priority of an element (i.e., the order in which it is deleted) determines the order in which elements in a priority queue are served. The components are served in the order they appear in the queue if they have the same priority.
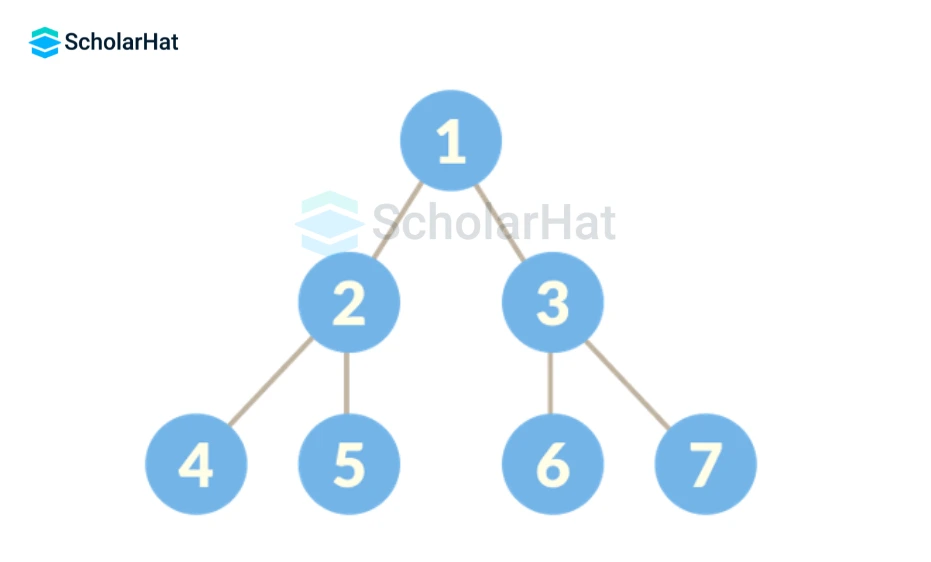
Q31. Define the Tree data structure.
A single node is identified as the tree's root, while the remaining nodes are referred to as the root's progeny. The Tree is a recursive data structure comprising one or more data nodes. All nodes that have the root node are divided into nonempty sets, with each node being referred to as a sub-tree.
Q32. List the many types of trees.
The following lists the six different kinds of trees:
- General Tree
- Forests
- Binary Tree
- Binary Search Tree
- Expression Tree
- Tournament Tree
Q33. Explain the meaning of binary trees and their uses.
A binary tree in a data structure is used to arrange data so that it may be efficiently retrieved and altered. It is a data structure in which the data is represented by two nodes, referred to as leaves and nodes.
Q34. What does a data structure's hashmap mean?
With the right key, data can be accessed in constant time (O(1)) complexity using the hashmap data structure, which is an implementation of a hash table data structure.
|
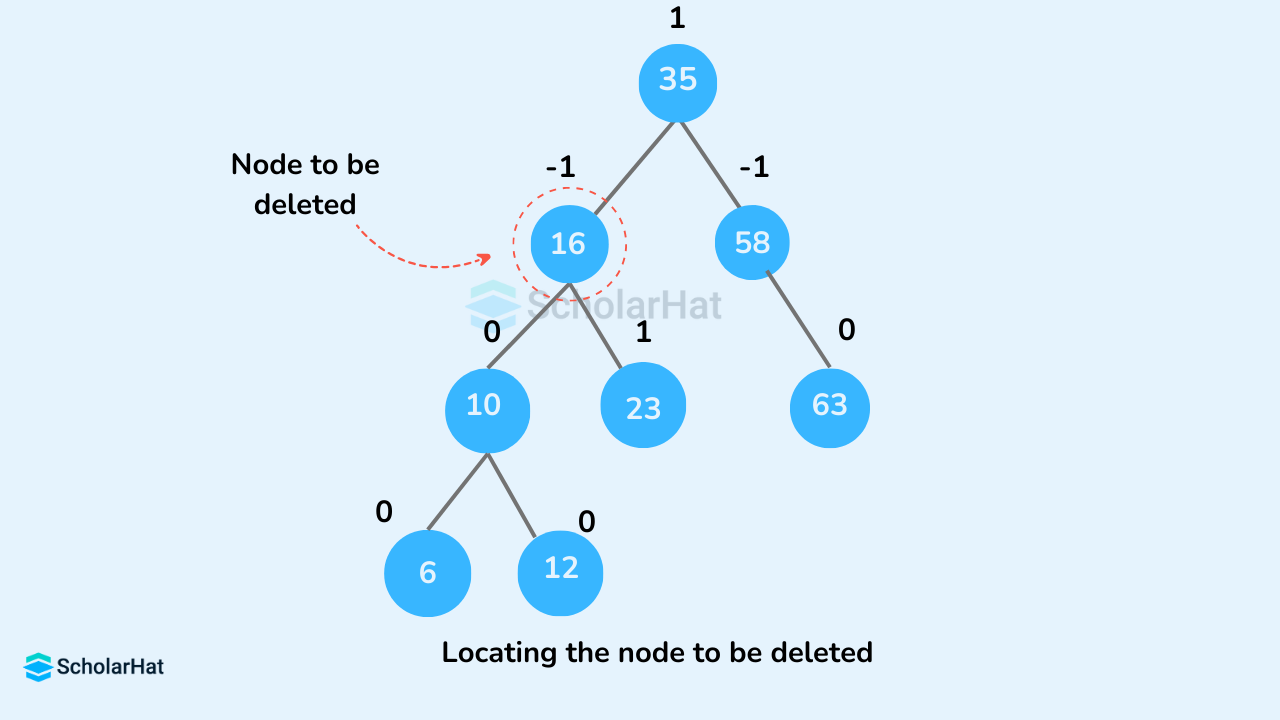
Q35. Describe an AVL tree.
A height-balancing binary search tree known as an AVL (Adelson, Velskii, and Landi) tree occurs when the difference between the heights of a node's left and right subtrees is either zero or less than one. This prevents the binary search tree from becoming skewed, therefore controlling its height. When working with a huge data set, this is used to continuously prune the data by adding and removing entries.
DSA Interview Questions for Experienced
For experienced candidates, these questions focus on advanced data structures, algorithm optimization, and real-world problem-solving to test your deep understanding.
Q36. What functions do AVL trees provide?
On the AVL tree, we are able to do the following two operations:
- Insertion: The procedure for inserting data into an AVL tree in the data structure is the same as that for a binary search tree. It might, however, result in an AVL tree property violation, necessitating the balance of the tree. The tree can be balanced by doing rotations.
- Deletion: Similarly to a binary search tree, deletion can also be carried out in this way. The tree's equilibrium might be upset by deletion, thus, several kinds of rotations are used to restore it.
Q37. What are the advantages of AVL trees over Binary Search trees?
The advantages of AVL trees over Binary Search Trees are as follows:
By preventing it from becoming skewed, the AVL tree regulates the height of the binary search tree. In a binary search tree of height h, the total processing time is O(h). But in the worst-case scenario, if the BST skews, it can be stretched to O(n). The AVL tree sets an upper limitation on each operation to be O(log n), where n is the number of nodes, by restricting this height to log n.
Q38. Explain the meaning of a B-tree data structure.
One kind of m-way tree that is frequently used for disc access is the B Tree. There can only be m-1 keys and m children in a B-Tree with order m. The capacity of a B tree to store a large number of keys in a single node and large key values while maintaining a relatively small tree height is one of the main justifications for its use.
 Distinguish between B+ and B-trees.
Distinguish between B+ and B-trees.| B Tree | B+ Tree |
| Search keys are not able to be repeatedly stored. | It is possible to have redundant search keys. |
| Both internal and leaf nodes have the capacity to store data. | Only the leaf nodes have the ability to store data. |
| Since data can be found on both internal and leaf nodes, searching for certain data takes longer. | Since data is only available on leaf nodes, searches are completed much more quickly. |
| Internal node deletion is quite difficult and time-consuming. | Since the element will always be eliminated from the leaf nodes, deletion will never be a complicated procedure. |
| Leaf nodes can't be connected to one another. | To improve the efficiency of search operations, leaf nodes are connected to one another. |
Q39. Provide some of the real-world applications for tree data structures.
Applications for the Tree data structure:
- Arithmetic expression manipulation
- Symbol Table Construction
- Syntax analysis
- Mode of hierarchical data
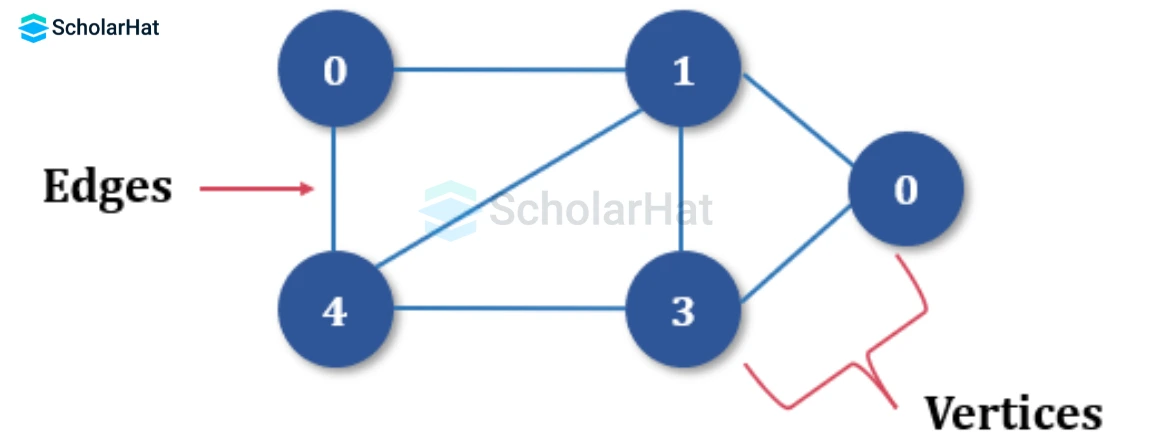
Q40. Explain the Graph data structure.
A non-linear data structure consisting of nodes and edges is called a graph data structure. In a network, nodes are also referred to as vertices, while edges are the lines or arcs that join any two nodes.
Q41. Recognise the differences on a graph between circuits, paths, and cycles.
- Path: A path is an unrestricted series of neighboring vertices joined by edges.
- Cycle: A closed path with the beginning and ending vertices being the same is called a cycle. No vertex in the path may be visited more than once.
- Circuit: A closed path in which the initial and final vertices are the same is known as a circuit. You can repeat any vertex.
Q42. Discuss the data structures that are often used in graph implementation.
The graph implementation makes use of the following data structures:
- Adjacency matrices in data structures are utilized in sequential representation.
- Adjacency lists data structures are used in linked representations.
Q43. What distinguishes the Depth First Search from the Breadth First Search?
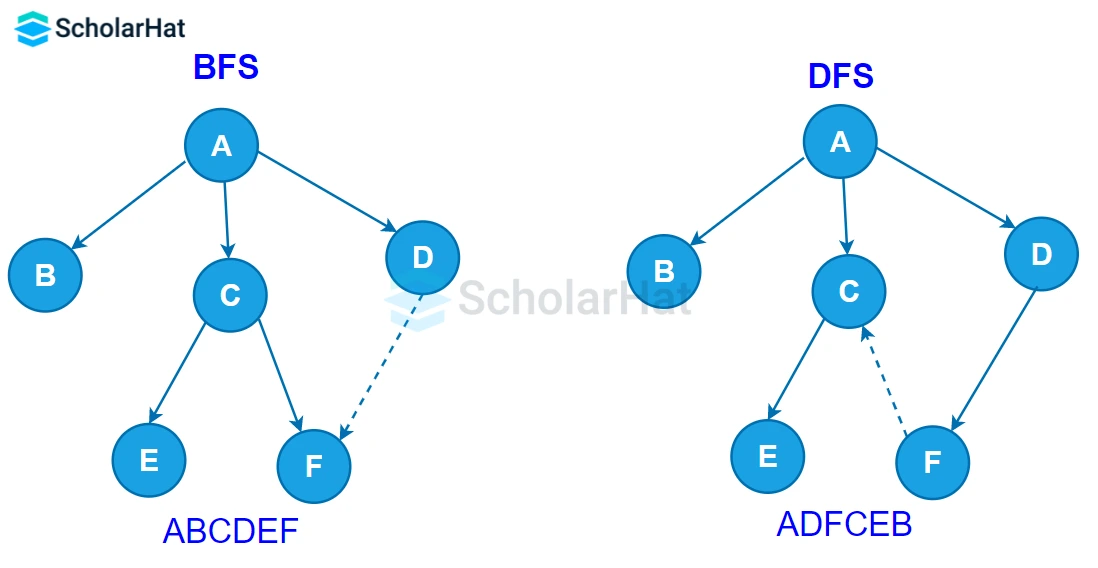
| Breadth First Search (BFS) | Depth First Search (DFS) |
| It is an abbreviation for "Breadth First Search." | It is an abbreviation for "Depth First Search." |
| The Queue data structure is used by BFS (Breadth First Search) to determine the quickest path. | The Stack data structure is used by DFS (Depth First Search) to determine the shortest path. |
| BFS is slower than DFS in this regard. | DFS is faster than BFS in this regard. |
| When the target is near the source, BFS operates more effectively. | When the target is far from the source, DFS operates more effectively. |
| BFS requires additional RAM. | RAM requirements for DFS are lower. |
| Nodes that have been visited more than once are eliminated from the queue. | The visited nodes are added to the stack and subsequently removed when there are no more nodes to visit. |
| In BFS, there is no way to go back. | The DFS algorithm utilizes the idea of backtracking and is recursive. |
| First In First Out, or FIFO, is the foundation of it. | The Last In First Out (LIFO) concept serves as its foundation. |
Q44. Describe how the Graph data structure is used.
The following are some applications for the graph:
- Circuit networks make use of graphs in which component wires serve as the graph's edges and points of connection as its vertices.
- Transport networks use graphs, with stations represented as vertices and routes as the graph's edges.
- Maps that depict cities, states, or regions as vertices and adjacency relationships as edges are made using graphs.
- Program flow analysis uses graphs, with calls to procedures or modules represented as edges and procedures or modules as vertices.
Q45. When is Binary Search appropriate to use?
An already-sorted list can be searched using the Binary Search algorithm in the data structure. The algorithm uses the divide-and-conquer strategy.
Q46. What are the benefits of Binary Search in comparison to Linear Search?
Because we make fewer comparisons during a binary search than during a linear search, it is more efficient. When using linear search, we can only remove one element from each comparison if we are unable to locate the desired value, but when using binary search, we can remove half of the set with each comparison. Compared to linear search, which takes O(n) time, binary search takes O(log n) time. This indicates that binary search in the data structure is faster than linear search when there are more elements in the search array.
|
Q47. What benefits does Selection Sort offer?
The benefits that Selection Sort offers are as follows:
- It is simple to understand and easy to use.
- Little data sets can be utilized using it.
- Comparing it to bubble sort, its efficiency is 60% higher.
|
Q48. Do dynamic memory allotments aid in data management?
Runtime basic structured data types are stored via dynamic memory allocation. It can be used to handle data of any size, in any order, by combining independently allocated structured blocks to create composite structures that can grow and shrink as needed.
Q49. Describe the distinction between VOID and NULL.
- Whereas Void is a data type identifier, Null is a value.
- While void denotes pointers with no initial size, null denotes an empty value for a variable.
- Null denotes nonexistence, while void indicates existence but inapplicability.
Q50. What is a heap data structure, and how does it work?
A heap is a special type of binary tree used for efficient priority queue operations. It follows the heap property, where the parent node is always greater (max-heap) or smaller (min-heap) than its child nodes. Heaps are commonly used in heap sort and Dijkstra’s algorithm.
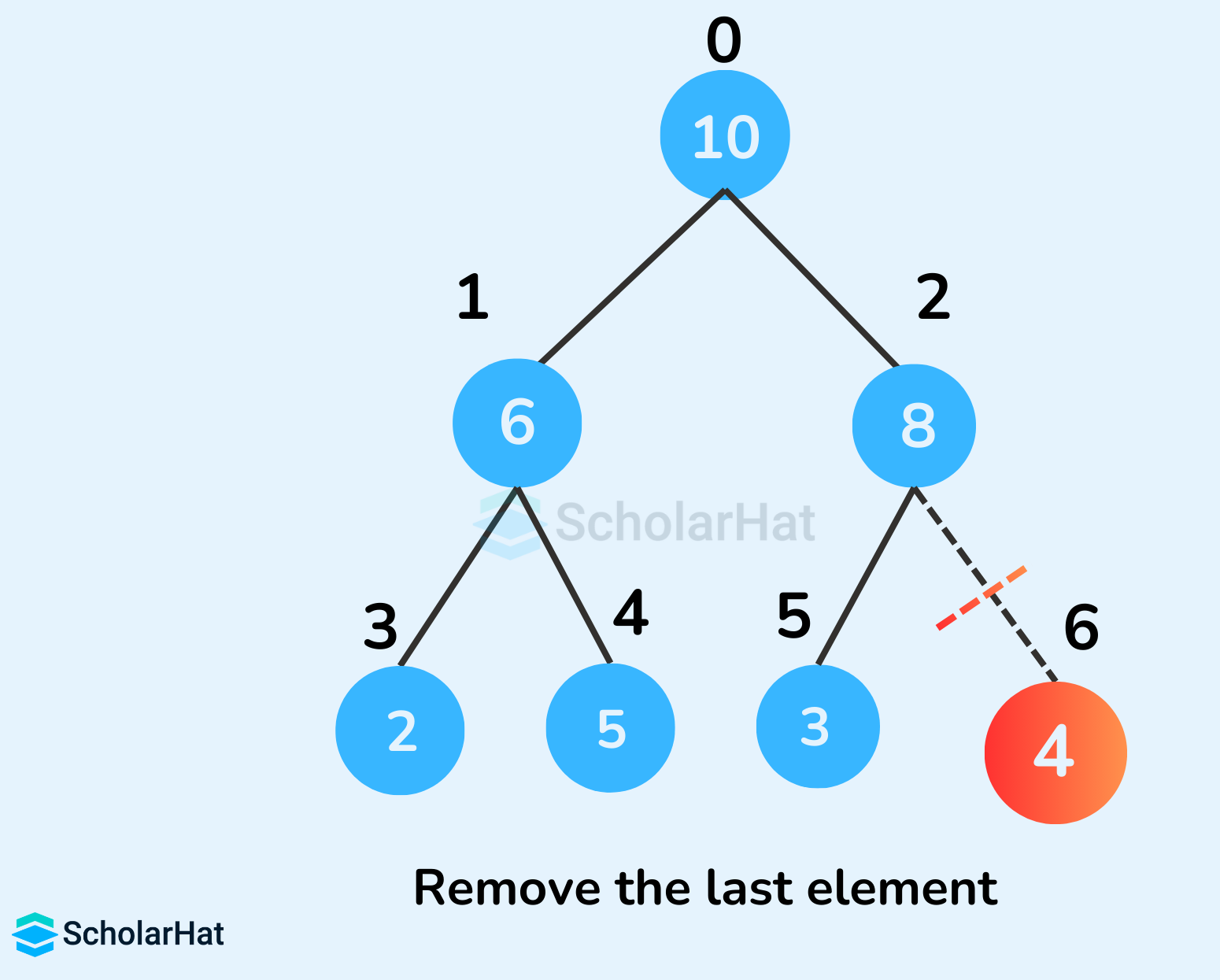
Q51. Explain the difference between a min-heap and a max-heap.
In a min-heap, the root node contains the smallest element, and every parent node is smaller than its child nodes. In a max-heap, the root node contains the largest element, and each parent node is greater than its children. Both structures allow efficient extraction of minimum or maximum values in O(log n) time.
Q52. What is a tree data structure, and where is it used?
A Trie (Prefix Tree) is a specialized tree data structure used for storing strings efficiently. It allows fast search, insert, and delete operations, making it useful in autocomplete systems, spell checkers, and IP routing.
Q53. What is the difference between a singly linked list and a doubly linked list?
A singly linked list contains nodes with a single pointer to the next node, allowing traversal in only one direction. A doubly linked list has two pointers, one pointing to the next node and another to the previous node, enabling bidirectional traversal and more efficient deletion operations.
Q54. What is hashing, and why is it used in data structures?
Hashing is a technique used to map data to a fixed-size table using a hash function. It provides efficient data retrieval in O(1) time in the best case. Hashing is widely used in databases, caching, and password storage.
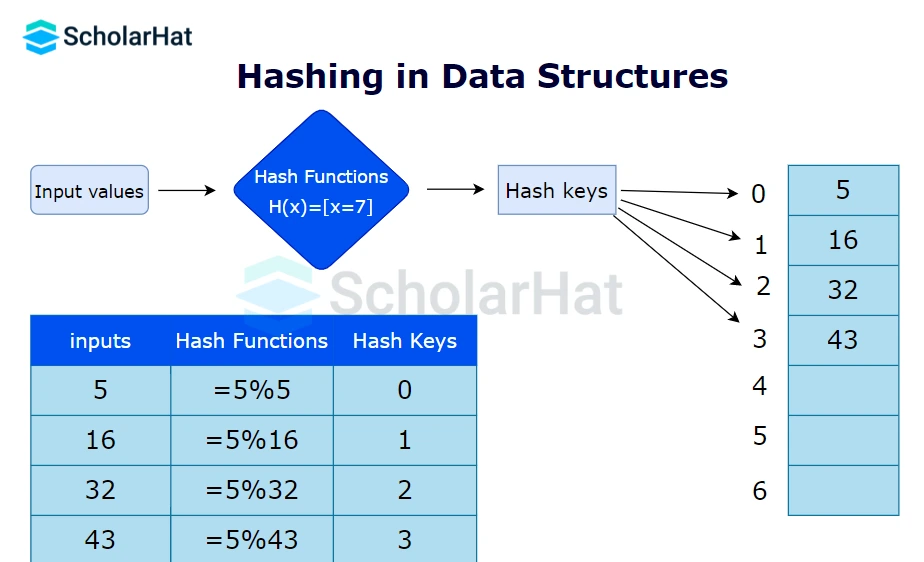
Q55. Explain collision in hashing and how to resolve it.
A collision occurs when two different keys produce the same hash value. This can be resolved using techniques like chaining (storing collided elements in a linked list) or open addressing (probing for the next available slot).
Q56. What is the difference between internal and external sorting algorithms?
Internal sorting algorithms process data entirely within the system's main memory (e.g., QuickSort, MergeSort), whereas external sorting algorithms handle large datasets that cannot fit in memory and require disk storage (e.g., External Merge Sort).
Q57. Describe the concept of backtracking in data structures.
Backtracking is a recursive algorithmic technique used to solve problems by exploring all possible solutions and discarding those that fail to meet conditions. It is used in N-Queens, Sudoku, and graph coloring problems.
Q58. What is a spanning tree in graph theory?
A spanning tree is a subgraph of a connected graph that includes all the vertices with the minimum number of edges and no cycles. It is used in network design and minimum spanning tree algorithms like Prim’s and Kruskal’s.
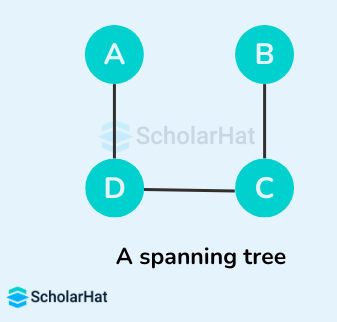
Q59. Explain the concept of dynamic programming in data structures.
Dynamic programming is an optimization technique used to break problems into smaller subproblems, solve them once, and store results to avoid recomputation. It is usedin theFibonacci sequence, theKnapsack problem, and theShortest Path algorithms.
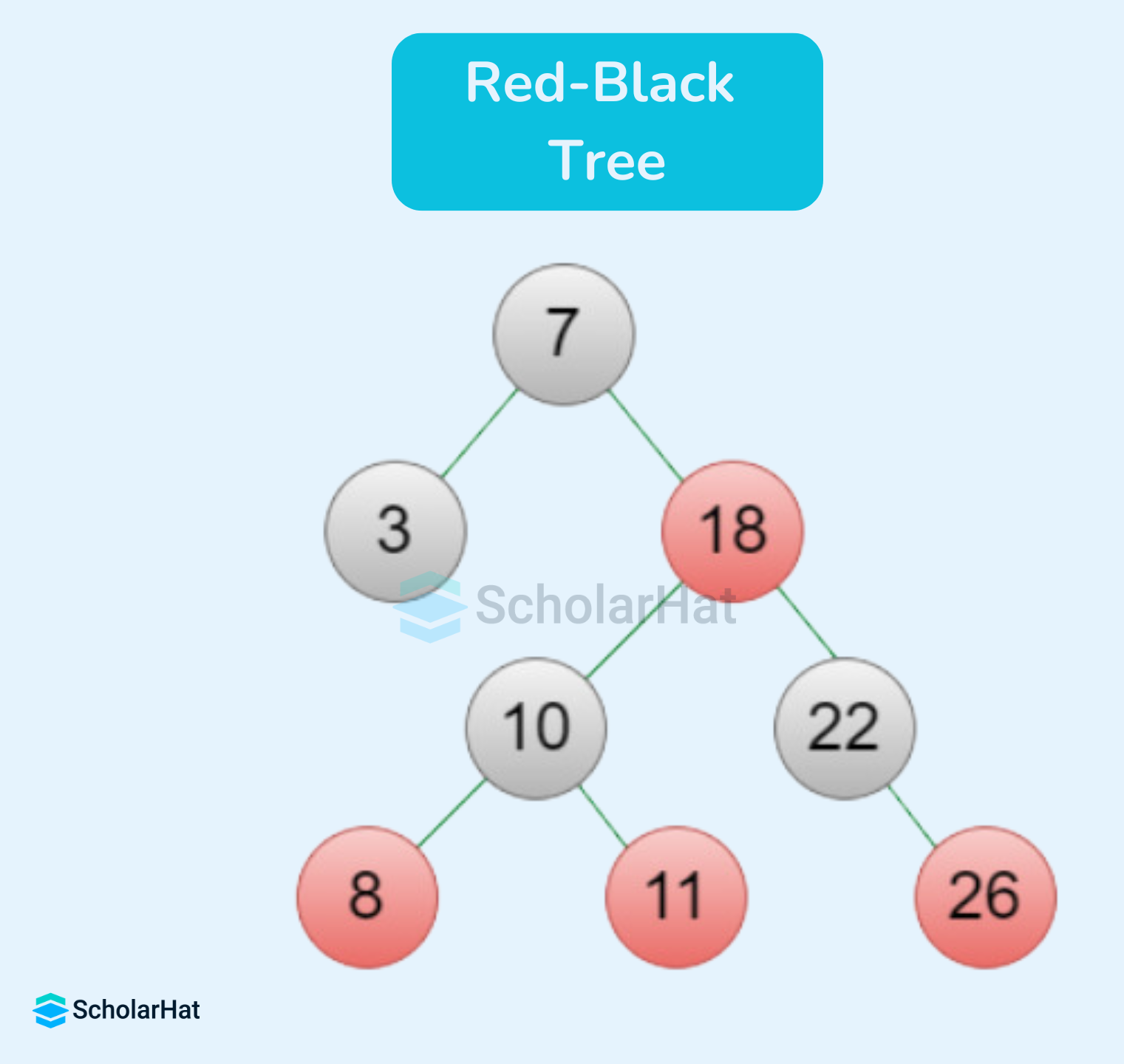
Q60. What is a red-black tree, and what are its properties?
A red-black tree is a self-balancing binary search tree that maintains balance through coloring rules. It ensures that operations like insertion and deletion occur in O(log n) time, making it useful in database indexing and memory management.
Summary
In this article, we looked at a wide range of important questions about data structures and algorithms, which are the foundation of modern software development. Learning these topics is very important, but it’s just the beginning. To truly succeed in interviews, regular and practical practice is the real key. Prepare effectively and boost your confidence with this DSA Certification Training.
Full-Stack Java Developers earn up to ₹38 LPA in India’s thriving tech market. Launch your high-paying career with our Full Stack Java Developer course today!
Download this PDF Now - DSA Interview Questions and Answers PDF By ScholarHatt |
Let’s climb to the top—test your knowledge and conquer every question
Q 1: Which data structure uses LIFO (Last In First Out)?
 Crack Your Next DSA Interview – Grab the Free Expert eBook!
Crack Your Next DSA Interview – Grab the Free Expert eBook!DSA Interview Questions and Answers Book Unlock expert-level DSA interview preparation with our exclusive eBook! Get instant access to a curated collection of real-world interview questions, detailed Answers Bookers, and professional insights — all designed to help you succeed.
No downloads needed — just quick, free access to the ultimate guide for DSA interviews. Start your preparation today and move one step closer to your dream job!.
Take our Datastructures skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.