








28
JunHash Table in Data Structures
23 Sep 2025
Advanced
11.8K Views
25 min read

Learn with an interactive course and practical hands-on labs
Free DSA Online Course with Certification
Hash Table in Data Structures: An Overview
In the previous tutorial, we saw what is hashing and how it works. We saw that a hash table is a data structure that stores data in an array format. The table maps keys to values using a hash function.
In this DSA tutorial, we'll explore the hash table in a little detail like its working, implementation, types, etc. By 2027, 80% of coding interviews will focus on DSA skills. Ace them with our Free Data Structures and Algorithms Course today!
What is a Hash Table in Data Structures?
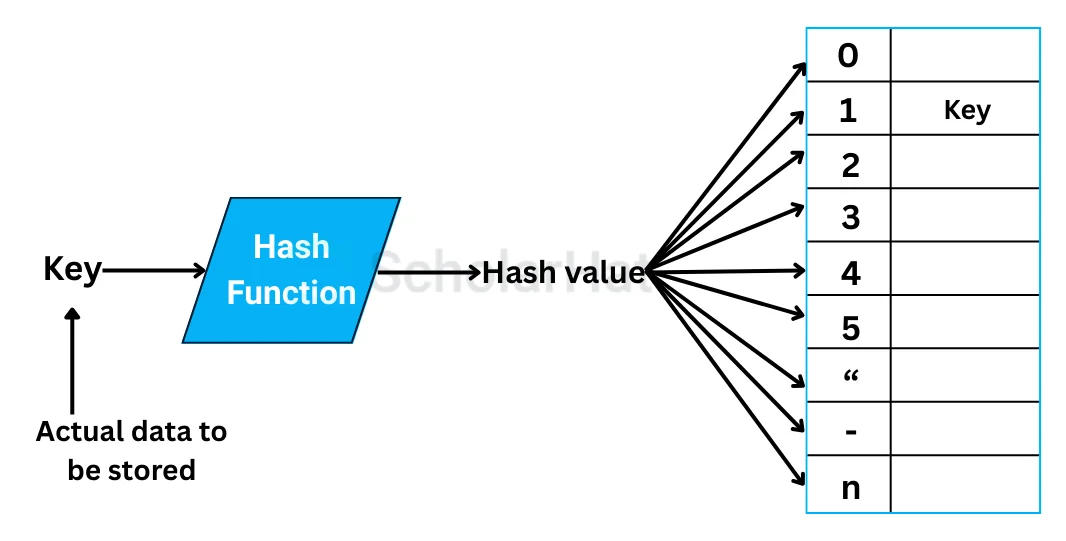
How Does the Hash Table Work?
- Initialize the Hash Table: Start with an empty array of a fixed size (let's say 10). Each index in the array represents a bucket in the hash table. [empty, empty, empty, empty, empty, empty, empty, empty, empty, empty]
- Insertion: When inserting a key-value pair into the hash table, the hash function is used to calculate the index where the pair should be stored. The hash function takes the key as input and returns an integer value.
Let's say we want to insert the key "apple" with the value "fruit" into the hash table. The hash function calculates the index as follows: hash("apple") = 5 Since the hash value is 5, we store the key-value pair in index 5 of the array: [empty, empty, empty, empty, empty, ("apple", "fruit"), empty, empty, empty, empty]
- Retrieval: To retrieve a value associated with a given key, we use the same hash function to calculate the index. We then look for the key-value pair in that index.
For example, if we want to retrieve the value for the key "apple," the hash function calculates the index as 5. We check index 5 in the array and find the key-value pair ("apple", "fruit"): [empty, empty, empty, empty, empty, ("apple", "fruit"), empty, empty, empty, empty]
- Collision: Hash tables can encounter collisions when two different keys map to the same index. This can happen if the hash function is not perfectly distributed or if the array size is relatively small compared to the number of keys.
For example, if we try to insert the key "banana" and the hash function calculates the index as 5, we encounter a collision. We search for the next available slot and find index 6 is empty. So, we store the key-value pair ("banana", "fruit") in index 6: [empty, empty, empty, empty, empty, ("apple", "fruit"), ("banana", "fruit"), empty, empty, empty] [empty, ("apple", "fruit"), ("banana", "fruit"), empty, empty, empty]
Read More - Data Structure Interview Questions and Answers
Hash Table Data Structure Algorithm
- Initialize an array of fixed size to serve as the underlying storage for the hash table. The size of the array depends on the expected number of key-value pairs to be stored.
- Define a hash function that takes a key as input and generates a unique hash code.
- To insert a key-value pair into the hash table, apply the hash function to the key to determine the index. If the calculated index is already occupied, handle collisions using a collision resolution strategy.
- To retrieve the value associated with a key, apply the hash function to the key to determine the index. If the index contains a value, compare the stored key with the given key to ensure a match. If the keys match, return the corresponding value. If the index is empty or the keys don't match, the key is not present in the hash table.
- To remove a key-value pair from the hash table, apply the hash function to the key to determine the index. If the index contains a value, compare the stored key with the given key to ensure a match. If the keys match, remove the key-value pair from the table. If the index is empty or the keys don't match, the key is not present in the hash table
Implementation of Hash Table in Different Programming Languages
def get(self, key):
index = self.hashFunction(key)
bucket = self.table[index]
for kvp in bucket:
if kvp[0] == key:
return kvp[1]
return "Key not found"
def remove(self, key):
index = self.hashFunction(key)
bucket = self.table[index]
for kvp in bucket:
if kvp[0] == key:
bucket.remove(kvp)
return
# Main function
if __name__ == "__main__":
hashTable = HashTable(10)
# Insert key-value pairs
hashTable.insert(1, "Value 1")
hashTable.insert(11, "Value 11")
hashTable.insert(21, "Value 21")
hashTable.insert(2, "Value 2")
# Retrieve values
print(hashTable.get(1)) # Output: Value 1
print(hashTable.get(11)) # Output: Value 11
print(hashTable.get(21)) # Output: Value 21
print(hashTable.get(2)) # Output: Value 2
print(hashTable.get(5)) # Output: Key not found
# Remove a key-value pair
hashTable.remove(11)
# Try to retrieve the removed value
print(hashTable.get(11)) # Output: Key not found
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
// Hash Table class
class HashTable {
// Bucket is a list of key-value pairs
private class KeyValuePair {
int key;
String value;
KeyValuePair(int key, String value) {
this.key = key;
this.value = value;
}
}
private List<LinkedList<KeyValuePair>> table;
private int size;
// Constructor
HashTable(int tableSize) {
size = tableSize;
table = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
table.add(new LinkedList<>());
}
}
// Hash function
private int hashFunction(int key) {
return key % size;
}
// Insert a key-value pair into the hash table
void insert(int key, String value) {
int index = hashFunction(key);
LinkedList<KeyValuePair> bucket = table.get(index);
// Check if the key already exists in the bucket
for (KeyValuePair kvp : bucket) {
if (kvp.key == key) {
// Key found, update the value
kvp.value = value;
return;
}
}
// Key not found, add a new key-value pair
bucket.add(new KeyValuePair(key, value));
}
// Retrieve the value associated with a given key
String get(int key) {
int index = hashFunction(key);
LinkedList<KeyValuePair> bucket = table.get(index);
// Search for the key in the bucket
for (KeyValuePair kvp : bucket) {
if (kvp.key == key) {
// Key found, return the value
return kvp.value;
}
}
// Key not found
return "Key not found";
}
// Remove a key-value pair from the hash table
void remove(int key) {
int index = hashFunction(key);
LinkedList<KeyValuePair> bucket = table.get(index);
// Search for the key in the bucket
for (KeyValuePair kvp : bucket) {
if (kvp.key == key) {
// Key found, remove the pair
bucket.remove(kvp);
return;
}
}
}
}
// Main function
class Main {
public static void main(String[] args) {
HashTable hashTable = new HashTable(10);
// Insert key-value pairs
hashTable.insert(1, "Value 1");
hashTable.insert(11, "Value 11");
hashTable.insert(21, "Value 21");
hashTable.insert(2, "Value 2");
// Retrieve values
System.out.println(hashTable.get(1)); // Output: Value 1
System.out.println(hashTable.get(11)); // Output: Value 11
System.out.println(hashTable.get(21)); // Output: Value 21
System.out.println(hashTable.get(2)); // Output: Value 2
System.out.println(hashTable.get(5)); // Output: Key not found
// Remove a key-value pair
hashTable.remove(11);
// Try to retrieve the removed value
System.out.println(hashTable.get(11)); // Output: Key not found
}
}
#include <iostream>
#include <vector>
#include <list>
// Hash Table class
class HashTable {
private:
// Bucket is a list of key-value pairs
typedef std::pair<int, std::string> KeyValuePair;
typedef std::list<KeyValuePair> Bucket;
std::vector<Bucket> table;
int size;
public:
// Constructor
HashTable(int tableSize) : size(tableSize) {
table.resize(size);
}
// Hash function
int hashFunction(int key) {
return key % size;
}
// Insert a key-value pair into the hash table
void insert(int key, const std::string& value) {
int index = hashFunction(key);
Bucket& bucket = table[index];
// Check if the key already exists in the bucket
for (auto& kvp : bucket) {
if (kvp.first == key) {
// Key found, update the value
kvp.second = value;
return;
}
}
// Key not found, add a new key-value pair
bucket.push_back(std::make_pair(key, value));
}
// Retrieve the value associated with a given key
std::string get(int key) {
int index = hashFunction(key);
Bucket& bucket = table[index];
// Search for the key in the bucket
for (const auto& kvp : bucket) {
if (kvp.first == key) {
// Key found, return the value
return kvp.second;
}
}
// Key not found
return "Key not found";
}
// Remove a key-value pair from the hash table
void remove(int key) {
int index = hashFunction(key);
Bucket& bucket = table[index];
// Search for the key in the bucket
for (auto iter = bucket.begin(); iter != bucket.end(); ++iter) {
if (iter->first == key) {
// Key found, remove the pair
bucket.erase(iter);
return;
}
}
}
};
// Main function
int main() {
HashTable hashTable(10);
// Insert key-value pairs
hashTable.insert(1, "Value 1");
hashTable.insert(11, "Value 11");
hashTable.insert(21, "Value 21");
hashTable.insert(2, "Value 2");
// Retrieve values
std::cout << hashTable.get(1) << std::endl; // Output: Value 1
std::cout << hashTable.get(11) << std::endl; // Output: Value 11
std::cout << hashTable.get(21) << std::endl; // Output: Value 21
std::cout << hashTable.get(2) << std::endl; // Output: Value 2
std::cout << hashTable.get(5) << std::endl; // Output: Key not found
// Remove a key-value pair
hashTable.remove(11);
// Try to retrieve the removed value
std::cout << hashTable.get(11) << std::endl; // Output: Key not found
return 0;
}Output
Value 1
Value 11
Value 21
Value 2
Key not found
Key not found
Characteristics of a Good Hash Function
- Deterministic: A hash function should always produce the same hash value for the same input. This property ensures consistency and allows for easy verification and comparison.
- Uniform distribution: The hash function should evenly distribute the hash values across the output space. This property helps to minimize collisions and ensures that different inputs have a low probability of producing the same hash value.
- Fixed output size: A good hash function has a fixed output size, regardless of the input size. This property enables efficient storage and comparison of hash values.
- Fast computation: Hash functions should be computationally efficient to handle large amounts of data quickly. Speed is crucial for applications that involve hashing large datasets or frequently computing hash values.
- Avalanche effect: A small change in the input should result in a significant change in the output hash value. This property ensures that even a minor modification in the input leads to a completely different hash value, making it difficult to predict or reverse-engineer the original input.
- Resistance to collisions: While it is impossible to eliminate collisions (different inputs mapping to the same hash value), a good hash function minimizes their occurrence. It should be difficult to find two different inputs that produce the same hash value.
- Non-invertibility: Given a hash value, it should be computationally infeasible to determine the original input that generated it. This property provides security and helps protect sensitive information.
- Well-defined behavior: The hash function should have an unambiguous definition for all possible inputs. It should handle edge cases and corner cases gracefully, without producing unexpected results or errors.
- Security properties: For cryptographic applications, a good hash function should exhibit additional security properties such as resistance to preimage attacks (finding an input given its hash value) and second preimage attacks (finding a different input with the same hash value).
Examples of widely-used hash functions that possess these characteristics include:
- (Secure Hash Algorithm 3)
- BLAKE2
- MD5 (although it is considered less secure due to vulnerabilities)
Note that the choice of a hash function depends on the specific requirements of the application, and different hash functions may be suitable for different use cases.
Hash Collision
- A hash collision refers to a situation where two different inputs produce the same hash value or hash code when processed by a hash function. In other words, it occurs when two distinct pieces of data result in an identical hash output.
- Hash collisions can have practical implications depending on the context, e.g. in hash tables, collisions can lead to degraded performance if not handled efficiently.
- Cryptographic hash functions, used in areas like data security and digital signatures, have stricter requirements to prevent collisions. These functions aim to provide a high level of collision resistance, making it computationally infeasible to find two inputs that produce the same hash value.
Cryptographic hash collisions are of particular concern because they can undermine the integrity and security of cryptographic systems. Researchers and cryptographers continually evaluate and analyze hash functions to ensure their collision resistance and security properties, as vulnerabilities or weaknesses discovered in hash functions could have significant implications for various applications that rely on them.
Types of Hash Collision
There are primarily two types of hash collisions: accidental or random collisions and intentional or malicious collisions. Let's explore each type in more detail:- Accidental Collisions: Accidental collisions occur when two different inputs produce the same hash value due to the nature of hashing algorithms and the limited range of possible hash values. These collisions are unintended and usually considered rare and coincidental. The probability of accidental collisions depends on the quality of the hashing algorithm and the size of the hash space. Good hashing algorithms strive to minimize the chances of accidental collisions by distributing hash values uniformly across the output space.
- Intentional Collisions: Intentional collisions occur when an attacker purposefully generates two or more different inputs that produce the same hash value. These collisions are often the result of exploiting vulnerabilities or weaknesses in the hashing algorithm. Intentional collisions can be a significant security concern in various scenarios, such as digital signatures, certificate authorities, password hashing, and data integrity checks.
There are two main categories of intentional collisions:
- Preimage Attacks: In a preimage attack, an attacker tries to find any input that matches a given hash value. This type of attack is aimed at breaking the one-way property of a hash function, which means that it is computationally infeasible to determine the original input from its hash value.
- Collision Attacks: In a collision attack, an attacker aims to find two different inputs that produce the same hash value. The goal is to break the collision resistance property of a hash function, which ensures that it is computationally difficult to find any two inputs with the same hash value
Hash Table Applications
- Dictionaries: Hash tables are commonly used to implement dictionary data structures, where words or terms are associated with their definitions or values. Hashing allows for quick lookup and retrieval of definitions based on the provided key.
- Caching: Hash tables are employed in caching systems to store frequently accessed data. By using a hash table, the most recently used or important items can be stored, and retrieval can be performed in constant time, improving overall system performance.
- Symbol tables: In compilers and interpreters, hash tables are used to implement symbol tables. Symbol tables store information about variables, functions, classes, and other symbols used in a program. Hashing enables efficient lookup and manipulation of symbols during compilation or interpretation.
- Database indexing: Hash tables are used in database systems to implement indexing structures. Hash-based indexing allows for fast data retrieval based on a specific key or attribute, speeding up query processing in databases.
- Set membership: Hash tables are utilized to implement sets, where membership operations like adding, removing, and checking for the presence of an element are performed efficiently. Hashing allows for constant-time lookup and insertion operations, making sets suitable for tasks such as duplicate removal and membership testing.
- Caching of computed values: Hash tables are employed to store pre-computed results or expensive computations. By caching the results based on the input parameters, subsequent requests can be satisfied instantly, avoiding redundant calculations.
- Spell checkers: Hash tables are used in spell-checking algorithms to store a dictionary of valid words. By hashing the words, the algorithm can quickly check if a given word is present in the dictionary, helping identify potential misspellings.
- Cryptographic data structures: Hash tables are employed in cryptographic systems for tasks like password storage and digital signatures. Hash functions convert sensitive data into fixed-length hashes, and hash tables provide an efficient way to store and retrieve hashed values securely.
Summary
The hash table in data structures is a powerful and versatile algorithm that can be used to store and easily access data. It is a comprehensive search mechanism that allows for the efficient retrieval of values without wasting computing resources. By utilizing hash tables, organizations can quickly index large datasets and accomplish their tasks more efficiently. Additionally, it helps in categorizing the elements into appropriate buckets dependent on some calculated value before performing any search.
Master Java full stack skills and boost your salary by 28% to ₹22-35 LPA. Enroll in our Java developer course and unlock top-tier earnings!
FAQs
A Hash table is a data structure used to insert, look up, and remove key-value pairs quickly.
A hash collision refers to a situation where two different inputs produce the same hash value or hash code when processed by a hash function.
There are primarily two types of hash collisions: accidental or random collisions and intentional or malicious collisions.
Take our Datastructures skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.