
25
JunData Processing in Machine Learning - Data Processing Cycle & Methids
27 Jul 2025
Advanced
8.95K Views
7 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
Introduction
A key component of machine learning is data processing, which is the manipulation or transformation of unprocessed data to make it appropriate for modeling and analysis. It starts with gathering data from numerous sources and progresses through several stages. After being gathered, the data is cleaned to remove mistakes, discrepancies, and missing numbers. If data is collected from many sources, integration might be necessary to provide a consistent dataset. To improve the data's representation, transformation techniques like scaling, normalization, and encoding are used. Identifying useful features and developing new ones are assisted by feature selection and engineering, respectively. To assess model performance, the dataset is then divided into testing, validation, and training sets. Techniques for data augmentation can be used to overcome restrictions like incomplete or unbalanced data.
Data processing in machine learning
Data processing in machine learning, which includes a number of procedures and methods that transform unprocessed information into a format appropriate for analysis and modeling, is an essential part of machine learning. Its importance stems from the fact that the applicability and quality of data have a significant influence on the precision and effectiveness of machine learning methods. Machine learning algorithms may successfully learn patterns, generate precise predictions, and derive insightful information for a variety of applications & decision-making processes through thorough data preparation and processing. The data processing in machine learning involves a number of crucial steps, including data cleansing, integration, transformation, feature selection, as well as information splitting.
The first phase is data cleaning, which identifies and fixes mistakes, discrepancies, & missing values in the dataset to improve data quality. When data is gathered from several sources, integration is necessary to combine and consolidate the datasets into a single, comprehensive dataset. Feature scaling, normalization, and categorical variable encoding are a few of the techniques used in data transformation, which is the process of transforming raw data into a format that can be used for analysis. The goal of feature selection is to find the most pertinent and useful features that significantly aid in the target prediction task. In order to assess model performance and avoid overfitting, data splitting divides the data set into testing, validation, and training sets.
Data Processing Cycle
The continual process of transforming & analyzing data to train and enhance machine learning models is known as the "data processing cycle" in machine learning. It entails a set of actions that are frequently repeated until successful results are obtained.
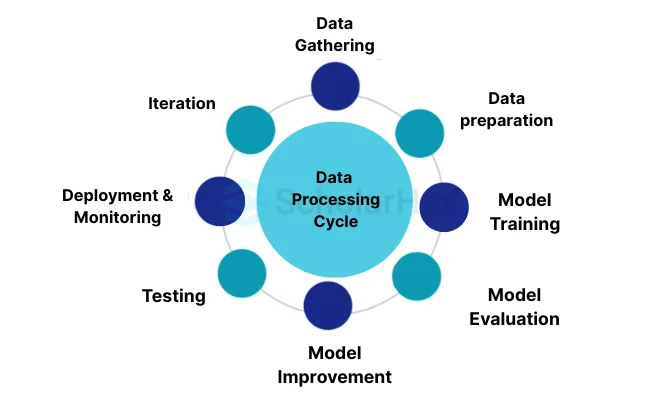
- Data Gathering: Gathering pertinent data from numerous sources, including databases, files, and online platforms, is the initial stage. Depending on the particular issue, the data may include characteristics, labels, or target variables.
- Data preparation: In this process, the data is cleaned to get rid of mistakes, discrepancies, and missing values. Additionally, it entails formatting the data in a way that is appropriate for analysis, such as processing text or picture data, scaling numerical features, or encoding categorical variables.
- Model Training: During this phase, a model based on machine learning is trained using the preprocessed data. The model attempts to identify patterns and connections between the features as well as the target variable by learning from the input data.
- Model Evaluation: Following training, the effectiveness of the model is assessed using cross-validation methods or validation data. The model's ability to forecast the target variable and complete the desired task is measured using a variety of criteria.
- Model Improvement: Changes are made to the model's operation based on the findings of the evaluation. This could entail modifying the model's architecture, adjusting the hyperparameters, or adding new features.
- Testing: Using test data that hasn't been seen before, the improved model is put to the test. This step offers an unbiased evaluation of the model's capacity for generalization as well as how well it operates in previously untested situations.
- Deployment and Monitoring: The model can be deployed for use in real-world applications if it operates well on the test data. It is possible to spot any deterioration or required improvements by tracking the model's performance over time as well as gathering feedback.
- Iteration: Since data processing cycles are frequently iterative, the aforementioned stages are repeated as necessary. To continuously develop the model and react to shifting circumstances, new data can be gathered, & the preprocessing, training, evaluation, & improvement phases can be repeated.
Methods of data processing
In order to use the data for training a model, it must first be transformed and prepared, which is known as data processing. Here are some typical ways that methods of data processing:
- Data Cleaning: Data cleaning entails addressing missing numbers, dealing with outliers, & removing or fixing flaws in the dataset. The mean, median, or interpolation approaches can be used to impute missing data. Statistical techniques can be used to identify and handle outliers, or domain expertise can be used to alter or eliminate them.
- Data Transformation: Data transformation entails changing or scaling the data to satisfy the presumptions or specifications of the selected machine learning algorithm. Common methods include standardization (scaling to zero mean and unit variance), logarithmic transformation, and normalization (scaling features to a given range).
- Engineering of features: To improve the data's representation and prediction ability, engineering features entails developing new features or altering current features. One-hot encoding, which turns categorical variables into binary vectors, feature scaling, dimensionality reduction (like PCA), and the creation of interaction or polynomial features are a few examples of methods that can be used for this.
- Data Integration: The process of merging data from several sources or formats into a single cohesive dataset is known as data integration. It entails addressing discrepancies, dealing with duplicate records, and merging data based on shared keys or identifiers.
- Data Sampling: To address class imbalance or to condense the dataset while keeping its representativeness, data sampling techniques are used. To balance the class distribution, methods like SMOTE (Synthetic Minority Over-sampling Technique), undersampling, and oversampling might be used.
- Data Splitting: Data splitting is the process of breaking up a dataset into training, validation, and testing sets. The testing set offers an unbiased evaluation of the final model's generalization, while the training set is used to train the model, the validation set aids in tuning hyperparameters and evaluates model performance.
- Data Augmentation: Data augmentation is the process of creating new training examples from the existing data by applying random changes or perturbations. This method helps in expanding the training set's diversity and size, which can enhance the model's capacity to generalize to previously undiscovered data.
Summary
Data transformation into a format appropriate for analysis and modeling is a crucial step in the machine learning process. Machine learning algorithms may discover patterns, generate precise predictions, and derive valuable insights for a variety of applications & decision-making processes by carefully processing and prepping the data. The stages of the data processing cycle include data gathering, preprocessing, training models, assessment, enhancement, testing, deployment, & monitoring.
Preprocessing comprises cleaning up the data and putting it into a format that is appropriate for analysis, whereas data collection entails acquiring pertinent data from various sources. The model that uses machine learning is trained using the preprocessed data, and its performance is then assessed. The model is enhanced by modifying hyperparameters or adding new features in response to the evaluation findings. The model's generalizability is tested using previously unreleased data. If the model performs satisfactorily, it can be used in practical applications, as well as its performance is tracked over time.
Data cleansing, integration, transformation, feature selection, as well as information injection, are some methods of data processing. While data integration merges data from several sources, data cleaning deals with mistakes and inconsistencies. Data representation is improved through transformational methods like scaling and normalization. Feature selection and engineering, on the other hand, seek appropriate characteristics and produce new ones. Techniques for enhancing data are used to overcome issues like incomplete or unbalanced data.