


01
AugWhat is Machine Learning? An Introduction to Machine Learning
27 Jul 2025
Beginner
10.9K Views
11 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
In today’s IT Industry or Software Development, one of the most emerging and highly discussed technology or rather better to say topics is Machine Learning. In the case of software designing and development, machine learning has a huge impact. Because with the help of machine learning, we can use data to finalize the business rules and logic. But how machine learnings are different in this concept? In traditional software development, developers write logic based on the current state of the business flow and then add the related data. But, since business process changes from time to time. So it totally impossible to predict what changes will affect the business market.
The benefit of machine learning is that it always provides us the facility to continuous learn from the business data and according to that predict the future business flow. Machine learning is always a set of powerful algorithms and models which are used across the industry so that process can be improved and we can retrieve much control and insights into the pattern of the data. But we need to remember, machine learnings is not a solitary endeavor. It is basically a team process which requires data scientists, data engineer, business analysts and business leaders to collaborate and analysis the business data so that they can plan the future business flow. There is no confusion that current business leaders are facing new and unexpected competitors nowadays. That’s why businesses are looking towards the new strategies that can prepare them for future survival. So, when a business tries some different strategies, then they all come back to a fundamental basic truth that we have to depend on the data and also need to follow the data. In this article, we will discuss the basic value and concept of Machine Learning.
What is Machine Learning?
Nowadays Machine Learning became one of the most emerging topics within the software development teams which depends on the data banks to help the business personals to achieve a new level of prediction and understanding. But the question is why we need to implement or use Machine Learning? Because with the help of appropriate machine learning models, organizations can obtain the ability to predict the changes in the business in the near future and according to that they can change their business path. As the data is continuously updated and added, that’s why machine learning models always ensure that the solution is also constantly updated. So the statement is very clear. If we use the most appropriate and constantly subjective data source in the context of machine learning, then we have the opportunity to predict the future.
So, Machine Learning is a form or process of Artificial Intelligence or AI which can provide a system which always learns from the data rather than through explicit programming. Actually, machine learnings is not a simple and straight forward process. Machine learning always contains a group of different types of algorithms that regularly learn from the data to improve the process, also can describe the data and predict the outcomes or results. As the business data totally trained by the proper algorithms, so it is possible to produce much more accurate model data for the business. Actually, the machine learning model is just the output generated when we run the machine learning algorithm with the data. After the training, when we provide the model with an input of data, we can obtain the output. Nowadays, machine learnings are very much essential for providing analytical models. Today, we most probably interact with a machine learning based application without realizing that. As an example, suppose we visit an e-commerce site and search for a specific product. Now, we visit another e-commerce site, that site also provides us a some suggested product list which related to my search product in the previous site. These types of programming are not done by hardcoded programming by the developers. These types of suggestions are mainly served via a machine learning model. The model checks your browsing history along with other shoppers’ browsing and purchasing data in order to present a similar type of products that you searched in other sites.
Traditional Programming vs Machine Learning
Traditional Programming has become a more than century-old nowadays. Since a first computer program is written in the mid-1800s. traditional programming always refers to any manually created program which always uses input data and runs on a computer to return the output.
In the other hand, Machine Learning is now evolved just more than a decade ago as a new and advanced typed of the programming process to empowered the business, especially for the intelligence and embedded analytics data. In the machine learning process, we need to feed input data and output data through an algorithm to create a program. This program always capable to predict the future outcomes on the basis of the input data.
Types of Machine Learning
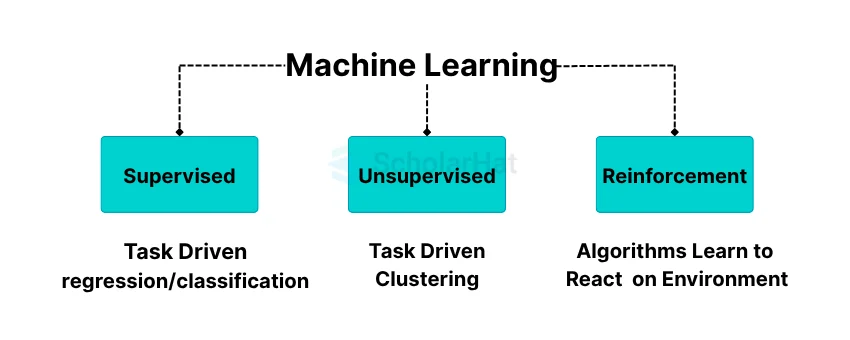
Machine Learnings can be categorized into three different parts. Three types of machine learnings are –
Supervised Machine Learning
Unsupervised Machine Learning
Reinforcement Learning
Supervised Machine Learning
The main objectives of the supervised machine learnings are to develop or trained a data model which make predictions based on the evidence of data. In a supervised learning algorithm, it takes a known set of data as input and also takes known set of result or response of that data as output and then it trains the model to generate reasonable predictions for the response to the new data. Supervised machine learning algorithms always try to apply the logic based on the past data to the new data and as per that analysis, it will predict the future events. The learning algorithm can be compared with its output with the actual result, intended or predicted the result and can find errors in the model so that the algorithm can be changed to modify the model accordingly.
Supervised machine learning algorithms normally used classification and regression techniques to develop and prepare the trained data model.
Classification techniques always predict a discrete response as a result. As for example, whether a particular is a spam mail or not, or whether a tumor is in the final stage or begin the stage. In these techniques, the classification model categories the input data into different categories. A typical application like medical imaging, speech recognition, credit scoring, etc. is normally used the classification techniques to predict the result.
In the case of Regression techniques, it always predicts continuous responses like changes in temperature or fluctuations in electricity demand. Applications like electricity load forecasting, temperature forecasting normally used these types of techniques to predict the result.
Unsupervised Machine Learning
Unsupervised learnings always find the hidden patterns or intrinsic structures within the data model. It is always trying to draw an inference from the data models in spite of labeling the data samples. Basically, unsupervised machine learning process always acquires the feature set from input data, not the label set like supervised techniques. Unsupervised machine learning algorithms are normally used when the data model need to train is neither classified nor labeled. In this system, the algorithm studies the data model to infer a function or reference to describe a hidden structure from the unlabeled data. So the system does not figure out the right output, but it analyzes the data and can draw inferences from the datasets to describe the hidden structured with the data model. Clustering is the most common unsupervised learning techniques. It is normally used for exploratory data analysis to find the hidden patterns or populate grouping within the data. Applications like market research, generic sequence analysis are normally using these types of machine learning techniques.
Reinforcement Learning
Reinforcement machine learning algorithms always interacts with its surrounding environments so that they can produce related actions for discovering errors or results. This process is always working on a trial and error search way. One of the most relevant characteristics of this process is the delayed result. Reinforcement machine learning algorithms always allow identifying the ideal behavior within a specific context in order to maximize the performance of the process. In the end, simple reward feedback is always required for the process algorithms to identify which one action is the best. This is normally known as the reinforcement signal.
The Machine Learning Workflow
As we already mentioned in the earlier section of this article that machine learning is basically all about developing trained data models in order to evaluate and understand the data. The entire learning process begins when we provide a machine learning model to adjust its internal parameters and also we can tweak these parameters so that the model can explain and analyze the data better. This entire process is normally known as a machine learning workflow. So, machine learning workflow can be described in many ways as per the process to train the data models. But still, the basic ML workflow will remain the same and it consists of the below stages:-
Source and prepare your data
Develop our data model
Train a Machine Learning Model on our data model and evaluate data accuracy
Now, deploy your trained model
Send the prediction request to your model
Analyze the predictions on an ongoing process
Update the model and model version as per the new data combinations
Machine Learning Use Cases
Now, a common question will automatically raise in our mind that When we need to use Machine Learning? So, consider machine learning only when we have a complex task or have a problem which involves a large volume of data and lots of variables, but it does not contain any formula or equation. As for example, machine learning is good for the below situations like –
Handwritten rules and equations are very complex as like speech recognition or face recognition.
The rule of a task is continuously changing – as in case of fraud detection in the transactions records.
The nature of the data keeps changing always and according to that program need to adopt that changed data like automated trading, energy demand, shopping trend predictions, etc.
Machine Learning Tools and Framework
Machine Learning Tools or framework can be an interface, library or tool which allow developers to build machine learning models in a very easy manner. The most popular machine learning languages are –
Python – A popular language with high-quality machine learning and data analysis libraries.
C++ - A middle-level language used for Parallel Computing on CUDA.
R – A language for statistical computing and graphics.
Some of the important tools for Data Analytics and Visualizations are –
Pandas – A python data analysis library enhancing analytics and modeling
Matplotlib – a python machine learning library for quality visualizations
Upyter Notebook – its a free web application for interactive web computing
Tableau – Powerfull data exploration capabilities and interactive visualization
The most popular and used Machine Learning frameworks are –
Amazon Machine Learning
Apache Mahout
Apache MXNet
Apache Singa
Caffe2
H2O
Microsoft Cognitive Toolkit
Scikit Learn
Tensor Flow
Theano
The Future of Machine Learning
Machine Learning would be a competitive benefit to any company either its top MNC or a startup company. Because currently all the things in the company done by manually which will be replaced by the machine in the future with the help of machine learning. So, the revolution of the machine learnings will be staying with us for a long time and so, definitely, it will be future of Machine Learning.
Summary
So, nowadays, Machine Learning is one of the most popular techniques for any application developer. Since we assume that this will solve our many problems and predicts the product expected result as per the trained data model. So in this article, we discuss the basic concept of machine learning along with different types of machine learning. Also, we have discussed some mostly used machine learning related tools and framework along with languages.