


31
JulMachine Learning Cheat Sheet : A Step-by-Step Guide
02 Sep 2025
Advanced
1.53K Views
24 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
Machine Learning Cheat Sheet serve as compact, easy-to-navigate guides that summarize essential concepts, models, and workflows in machine learning. They are designed to help learners, practitioners, and professionals quickly grasp the fundamentals, compare algorithms, understand model evaluation techniques, and make informed decisions during real-world ML tasks or interviews.
Hence, In this Machine Learning Cheat Sheet , we will explore all types of concepts of ML . So Let's Start.
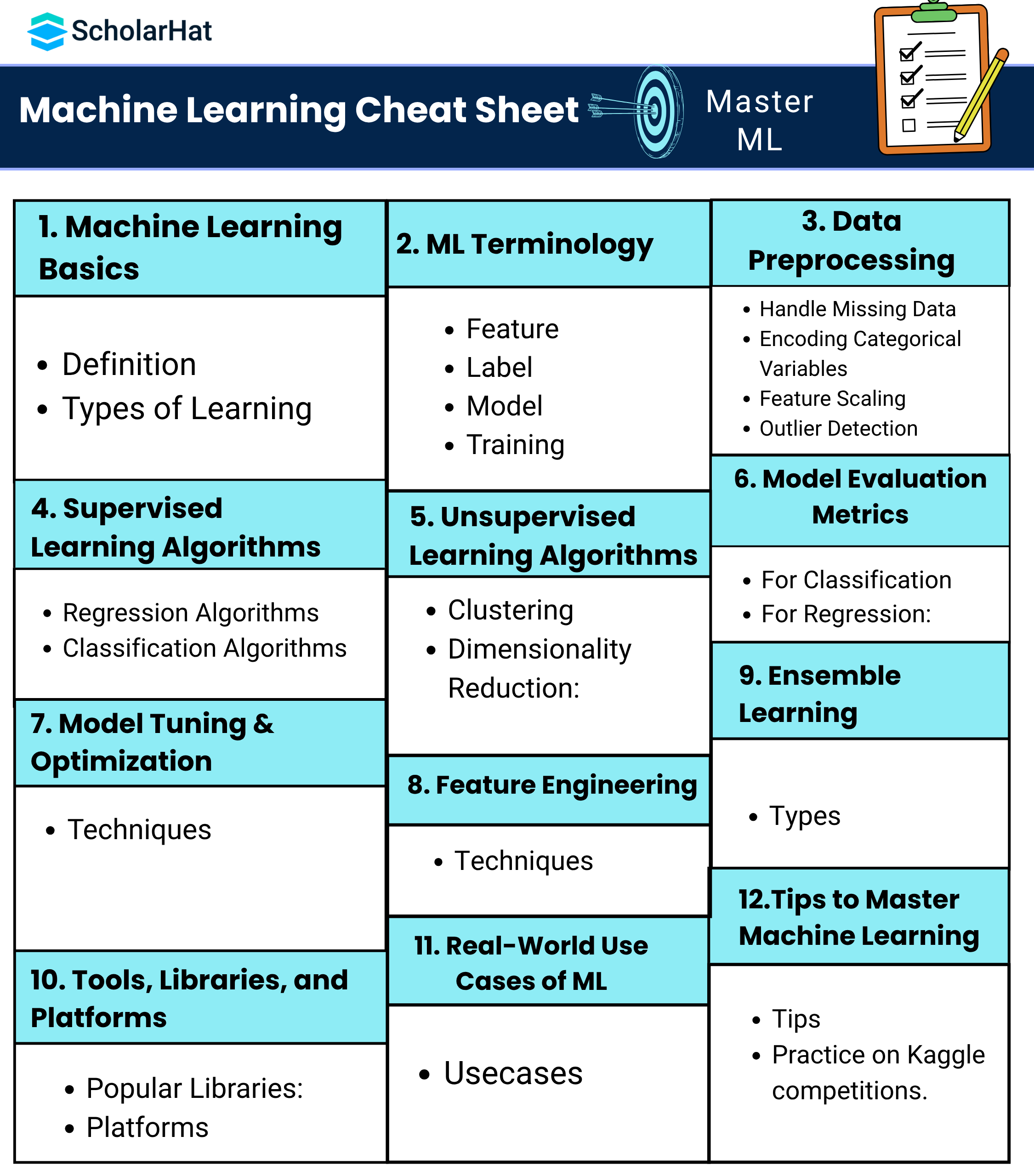
Step 1: Understand What Machine Learning Is
What is Machine Learning?
Machine Learning ML is a branch of Artificial Intelligence AI that enables computers to learn from experience data and improve their performance on tasks over time without being explicitly programmed. Instead of writing specific instructions for every scenario, we provide the machine with data, and it learns patterns or relationships from that data to make decisions or predictions.

Types of Machine Learning
1. Supervised Learning
- What it means: The algorithm learns from labeled data, where each input has a corresponding correct output.
- Examples:
- Classification: Predicting categories, such as spam or not spam in emails.
- Regression: Predicting continuous values, such as house prices.
- Real-world use: Email spam filters, loan approval prediction, disease diagnosis.
2. Unsupervised Learning
- What it means: The algorithm works with unlabeled data and tries to find hidden patterns or groupings.
- Examples:
- Clustering: Grouping similar items, such as customer segmentation.
- Association: Discovering rules, such as people who buy bread also buy butter.
- Real-world use: Market basket analysis, recommendation systems, social network analysis.
3. Semi-supervised Learning
- What it means: Combines a small amount of labeled data with a large amount of unlabeled data to improve learning accuracy.
- Example: A few labeled medical scans and thousands of unlabeled ones used together to train a disease detection model.
- Real-world use: Image and speech recognition where labeling all data is expensive.
4. Reinforcement Learning
- What it means: An agent learns to make decisions by interacting with an environment and getting rewards or penalties based on its actions.
- Example: A robot learns to walk by receiving positive rewards when it moves correctly.
- Real-world use: Game AI such as AlphaGo, robotics, self-driving cars, stock trading bots.
Step 2: Essential ML Terminology
Before diving deeper into machine learning algorithms and techniques, it's important to understand some core terms that form the foundation of any ML conversation. These terms will help you communicate more effectively, debug models, and interpret results correctly.
Key ML Terms Explained
1. Feature
- What it is: An input variable used to make predictions.
- Example: In predicting whether a person will buy a product, features might include their age, income, or location.
- Real-world example: For a health diagnosis model, features could be heart rate, cholesterol level, and blood pressure.
2. Label
- What it is: The output variable we want to predict or classify.
- Example: In a spam filter, the label is whether the email is spam or not spam.
- Real-world example: In a loan approval system, the label is approved or rejected.
3. Model
- What it is: A mathematical function that learns the relationship between features and labels.
- How it works: After training, the model can take in new data and predict the label.
- Real-world example: Netflix's recommendation engine is a model trained on your watch history.
4. Training
- What it is: The process of feeding data to the model so it can learn the patterns.
- Includes: Both features and labels.
- Real-world example: Feeding thousands of labeled cat and dog images to help a model recognize animals.
5. Overfitting
- What it is: When the model learns the noise and details of the training data too well.
- Consequence: Great performance on training data but poor results on new, unseen data.
- Real-world analogy: A student memorizes past exam answers but cannot apply the concepts to a new question.
Underfitting
- What it is: The model is too simple and fails to capture the patterns in the data.
- Consequence: Poor performance on both training and test data.
- Real-world analogy: A student understands only basic formulas and fails at solving even slightly advanced questions.
Bias-Variance Tradeoff
- What it is: The balancing act between a simple model high bias, low variance and a complex model low bias, high variance.
- Goal: Find a model that generalizes well to new data by minimizing both bias and variance.
- Real-world example: Tuning a model's complexity to avoid both overfitting and underfitting, like choosing just the right amount of data and features to teach a student.
Step 3: Data Preprocessing
Before feeding any data into a machine learning model, it is crucial to clean, transform, and prepare the dataset. High-quality input data leads to accurate and reliable model predictions. This step is often called data preprocessing, and it ensures that your model learns from relevant, consistent, and scaled information.
Why Preprocessing Matters?
Raw data collected from real-world sources like databases, web scrapers, or sensors often contains missing values, inconsistencies, noise, or irrelevant formats. If used directly, this data can lead to misleading results, errors, or poor model performance.
Key Preprocessing Steps
1. Handle Missing Data
- What it is: Filling in or removing records where some feature values are missing.
- Methods:
- Mean or Median Imputation: Replace missing values with the average or median.
- Deletion: Remove rows or columns with missing values if the dataset is large enough.
- Real-world example: If a customer's age is missing in a dataset of 10000 records, you might replace it with the average age instead of deleting the entire row.
2. Encoding Categorical Variables
- What it is: Converting text-based categories into numeric values so the model can process them.
- Types:
- One-Hot Encoding: Creates binary columns for each category. For example, Red, Blue, Green becomes 100, 010, 001.
- Label Encoding: Assigns numeric labels to categories. For example, Red = 0, Blue = 1, Green = 2.
- Real-world example: Converting Gender into numbers where Male = 0 and Female = 1.
3. Feature Scaling
- What it is: Adjusting the range of numeric data so that all features contribute equally to the model.
- Techniques:
- Normalization MinMaxScaler: Scales values to a range between 0 and 1.
- Standardization StandardScaler: Transforms data to have a mean of 0 and standard deviation of 1.
- Real-world example: If income ranges from 10000 to 100000 and age ranges from 18 to 60, scaling them ensures one does not dominate the learning process.
4. Outlier Detection
- What it is: Identifying data points that are unusually high or low compared to others.
- Techniques:
- Z-Score: Measures how many standard deviations a point is from the mean.
- IQR Interquartile Range: Flags values that fall outside the expected quartile range.
- Real-world example: If most customer purchases are under 5000 and one is 100000, it may need to be investigated or removed.
5. Train-Test Split
- What it is: Dividing the dataset into two subsets — one to train the model and another to test its performance.
- Common Ratios: 70-30 or 80-20 training to testing.
- Real-world example: Out of 1000 records, use 800 to train the model and 200 to evaluate its accuracy on new data.
Step 4: Supervised Learning Algorithms
Supervised learning algorithms are trained on labeled datasets, where each input comes with a known output. The goal is to enable the model to learn the mapping between inputs and outputs so that it can predict outcomes for new, unseen data.
These algorithms are broadly categorized into two types based on the nature of the output:
Regression Algorithms (Predict Continuous Values)
Regression algorithms are used when the target variable is continuous, such as price, temperature, or age.
1. Linear Regression
- Predicts a target value by fitting a straight line through the data.
- Use-case: Predicting house prices based on size, location, and number of rooms.
2. Ridge and Lasso Regression
- Variants of linear regression with regularization to avoid overfitting.
- Ridge uses L2 penalty; Lasso uses L1 penalty and can eliminate unnecessary features.
- Use-case: Useful when you have many correlated features in your dataset.
3. Polynomial Regression
- Extends linear regression by fitting a curve instead of a straight line.
- Use-case: Predicting growth rates or population where data doesn’t follow a straight line.
4. Support Vector Regression (SVR)
- Uses the principles of Support Vector Machines to perform regression.
- Use-case: Predicting stock prices or real-estate trends where margin of tolerance is important.
Classification Algorithms (Predict Categories)
Classification algorithms are used when the target variable is categorical, such as spam or not spam, yes or no, or different class labels.
1. Logistic Regression
- Used for classification, not regression, despite the name.
- Uses the logistic function to model binary outcomes.
- Use-case: Email spam detection, disease diagnosis yes or no.
2. Decision Trees
- A tree-like model where each node represents a decision rule and each leaf a result.
- Use-case: Credit scoring, medical decision-making.
3. Random Forest
- An ensemble method of multiple decision trees to improve prediction accuracy and reduce overfitting.
- Use-case: Loan approval, fraud detection.
4. K-Nearest Neighbors (KNN)
- Classifies a data point based on the majority class of its 'k' closest neighbors.
- Use-case: Handwriting recognition, customer segmentation.
5. Support Vector Machines (SVM)
- Finds the best boundary hyperplane that separates classes in the feature space.
- Use-case: Face detection, document classification.
6. Naive Bayes
- Based on Bayes' Theorem and assumes features are independent.
- Use-case: Sentiment analysis, spam filtering.
7. Gradient Boosting (XGBoost, LightGBM)
- Ensemble techniques that build models in stages, correcting previous errors.
- Highly accurate and used in many competitions.
- Use-case: Ranking, sales forecasting, predictive maintenance.
Step 5: Unsupervised Learning Algorithms
The unsupervised learning algorithms are trained using unlabeled data. The model tries to find hidden patterns or groupings in the input data.
Clustering:
- K-Means: Partitions data into K distinct clusters based on distance.
- Hierarchical Clustering: Builds a hierarchy of clusters using agglomerative or divisive methods.
- DBSCAN: Density-Based Spatial Clustering; finds clusters based on data density and can handle outliers.
Dimensionality Reduction:
- PCA (Principal Component Analysis): Reduces the number of features while preserving as much variance as possible.
- t-SNE: A technique for visualization of high-dimensional data in 2 or 3 dimensions.
- LDA (Linear Discriminant Analysis): Reduces dimensions while maintaining class separability.
Step 6: Model Evaluation Metrics
Choosing the right evaluation metric is crucial to assess how well your machine learning model is performing. The choice depends on whether you are solving a classification or regression problem.
For Classification:
- Accuracy: The ratio of correctly predicted instances to total instances.
- Precision: The ratio of true positives to total predicted positives.
- Recall: The ratio of true positives to total actual positives.
- F1-Score: The harmonic mean of precision and recall.
- Confusion Matrix: A table showing true positives, false positives, true negatives, and false negatives.
- ROC-AUC: Measures the area under the Receiver Operating Characteristic curve; good for imbalanced datasets.
For Regression:
- Mean Absolute Error (MAE): Average of absolute differences between predicted and actual values.
- Mean Squared Error (MSE): Average of squared differences between predicted and actual values.
- Root Mean Squared Error (RMSE): Square root of MSE; gives higher weight to larger errors.
- R² Score: Indicates how well the model explains the variance in the target variable (1 is perfect prediction).
Step 7: Model Tuning & Optimization
After training a machine learning model, it’s important to optimize it to improve its accuracy and generalization ability. This step ensures your model performs well not just on training data but also on unseen data.
Techniques:
- Cross-Validation (K-Fold): Splits the data into K parts and trains the model K times, each time using a different part as validation and the rest for training. Helps in robust model evaluation.
- Grid Search / Random Search:
- Grid Search: Exhaustively tries all possible combinations of parameters to find the best one.
- Random Search: Randomly samples parameter combinations. Often faster and equally effective.
- Hyperparameter Tuning: Involves adjusting parameters (e.g., learning rate, number of estimators) to maximize model performance.
- Early Stopping (for deep learning models): Stops training when performance on the validation set starts degrading to prevent overfitting.
Step 8: Feature Engineering
Feature Engineering is one of the most crucial steps in the machine learning pipeline. It involves transforming raw data into meaningful features that help machine learning algorithms perform better. The quality of features can make or break a model's performance.
Techniques:
- Feature Creation: This involves generating new features from existing ones by combining or transforming variables. For example:
- Combining 'height' and 'weight' into a 'BMI' feature.
- Extracting 'day', 'month', or 'hour' from a 'timestamp'.
- Feature Selection: Not all features contribute equally to model performance. Some may introduce noise or redundancy. Feature selection techniques help identify and retain only the most relevant features:
- Correlation analysis: Remove highly correlated features that convey the same information.
- Feature importance scores: Use models like Random Forest or XGBoost to evaluate and rank feature significance.
- Removing Multicollinearity: Multicollinearity occurs when independent features are highly correlated, making it hard to understand the effect of each feature. Techniques like Variance Inflation Factor (VIF) help detect and remove multicollinear variables to make the model more stable and interpretable.
- Domain Knowledge-Based Features: Incorporating subject matter expertise can be a game-changer. For example, in a healthcare dataset, creating a feature like "Risk Score" based on known clinical rules can significantly enhance the model's predictive power.
Overall, thoughtful feature engineering improves model accuracy, reduces training time, and enhances interpretability.
Step 9: Ensemble Learning
Ensemble Learning is a powerful machine learning technique where multiple models (often called "weak learners") are combined to create a stronger overall model. The idea is that a group of models working together can produce more accurate and robust predictions than any individual model alone.
Types:
- Bagging (Bootstrap Aggregating):
Bagging works by training multiple versions of the same model on different subsets of the data (created through bootstrapping) and then aggregating their predictions. This technique helps reduce variance and prevents overfitting.
Example: Random Forest
- Multiple decision trees are trained on different samples of the data.
- The final prediction is made by averaging the predictions (for regression) or using majority voting (for classification).
- Boosting:
Boosting trains models sequentially, with each new model focusing on the errors made by the previous ones. It reduces bias and improves the model's accuracy over time.
Examples: Gradient Boosting, AdaBoost, XGBoost, LightGBM, CatBoost
- Each new model corrects the mistakes of its predecessor.
- More weight is given to the data points that were previously misclassified.
- The final prediction is a weighted sum of all model outputs.
- Stacking (Stacked Generalization):
Stacking combines predictions from multiple different models (e.g., logistic regression, decision trees, SVMs) using another model (meta-learner) to make the final prediction.
- Level-0 models are trained on the input data.
- Level-1 model (meta-model) is trained on the predictions of Level-0 models.
- This allows the ensemble to capture different aspects of the data by leveraging the strengths of various algorithms.
Step 10: Tools, Libraries, and Platforms
To effectively work in machine learning, it’s essential to be familiar with the tools, libraries, and platforms that make model development, experimentation, and deployment efficient and scalable. These resources empower data scientists and developers to focus more on problem-solving rather than reinventing the wheel.
Popular Libraries:
- Python Libraries:
- Scikit-learn: A user-friendly and efficient library for classical machine learning algorithms like classification, regression, clustering, and preprocessing.
- TensorFlow: An open-source library developed by Google for deep learning and numerical computation. Suitable for neural networks and large-scale ML pipelines.
- PyTorch: A dynamic deep learning framework developed by Facebook. Preferred for research and production due to its flexibility and ease of use.
- Keras: A high-level neural networks API, often used as a front-end for TensorFlow. It enables fast prototyping and experimentation.
- XGBoost: A powerful and scalable implementation of gradient boosting used in many Kaggle competitions. Known for performance and speed.
- R Libraries:
- caret: A comprehensive R package for training and evaluating machine learning models. It simplifies model tuning and validation.
- randomForest: Implements the Random Forest algorithm for both classification and regression tasks in R.
- e1071: Provides various machine learning algorithms including SVM, Naive Bayes, and k-means in R.
- Visualization Libraries:
- Matplotlib: The most commonly used plotting library in Python, great for line graphs, bar charts, histograms, etc.
- Seaborn: Built on top of Matplotlib, it offers a high-level interface for drawing attractive and informative statistical graphics.
- Plotly: An interactive graphing library that supports 3D charts, dashboards, and real-time data visualization.
Platforms:
- Google Colab: A free cloud-based Jupyter notebook environment that supports GPU and TPU acceleration. Ideal for collaborative experimentation and small-to-medium model training.
- Jupyter Notebook: An open-source web application that allows the creation and sharing of live code, visualizations, and narrative text. Widely used for prototyping and teaching.
- Kaggle: A platform for data science competitions, dataset hosting, and notebooks. Offers a free environment with pre-installed libraries and GPU access.
- AWS SageMaker: A fully managed service from Amazon that enables building, training, and deploying machine learning models at scale in the cloud.
- Azure Machine Learning: A Microsoft service that supports end-to-end ML workflows from data ingestion to model deployment and monitoring. Offers integration with other Azure tools.
Choosing the right tools and platforms depends on the project scale, computational resources needed, and the developer’s familiarity with the ecosystem. Mastery of these tools is essential for a career in machine learning.
Step 11: Real-World Use Cases of Machine Learning
Machine Learning (ML) is transforming industries by enabling systems to learn from data and make decisions with minimal human intervention. Its applications are wide-ranging, from predicting customer behavior to automating critical operations. Below are some real-world domains where ML is making a significant impact:
1. Finance:
- Credit Scoring: ML models analyze historical loan data, transaction patterns, income levels, and payment history to assess a borrower’s creditworthiness. This enables banks and financial institutions to make informed lending decisions with reduced risk.
- Fraud Detection: Machine learning algorithms detect unusual patterns or anomalies in transactions that might indicate fraudulent activity. These systems can continuously learn and adapt to new fraud techniques in real-time, enhancing security and compliance.
2. Healthcare:
- Disease Prediction: ML models process patient records, genetic information, and medical imaging to predict the likelihood of diseases like cancer, diabetes, or heart disease. This helps in early intervention and better patient outcomes.
- Drug Discovery: ML accelerates the drug development process by predicting how different compounds will interact with biological targets. It helps in identifying promising candidates faster and reduces R&D costs significantly.
3. E-commerce:
- Recommendation Engines: ML powers personalized product recommendations by analyzing user behavior, purchase history, and preferences. This not only improves user experience but also increases conversion rates and customer retention.
4. Marketing:
- Customer Segmentation: ML algorithms group customers based on demographics, behavior, and purchase patterns. Marketers can then target each group with customized messaging, improving engagement and ROI.
- Lead Scoring: ML helps prioritize sales leads by predicting which prospects are most likely to convert based on historical data and user interactions, enabling more efficient sales efforts.
5. Transport:
- Traffic Prediction: Using data from GPS, traffic cameras, and sensors, ML models forecast traffic congestion and suggest optimal routes. This helps in reducing travel time and fuel consumption.
- Self-Driving Cars: Autonomous vehicles use ML for real-time decision-making based on sensor data, GPS, camera feeds, and past driving patterns. They can detect obstacles, follow traffic rules, and navigate roads safely without human intervention.
These real-world use cases showcase the versatility and power of machine learning in solving complex problems, increasing operational efficiency, and delivering intelligent automation across industries.
Step 12: Tips to Master Machine Learning
Mastering Machine Learning is a journey that combines theoretical knowledge with practical application. Whether you’re a student, aspiring data scientist, or seasoned developer, following the right learning path and strategies can accelerate your success. Below are essential tips to guide you on your ML journey:
1. Start with Simple Projects
- Begin with beginner-friendly datasets like predicting house prices, classifying flowers (Iris dataset), or digit recognition (MNIST).
- Focus on understanding the data preprocessing, model building, evaluation, and improvement process rather than just results.
- These projects build your confidence and help you understand the ML pipeline end-to-end.
2. Practice on Kaggle Competitions
- Kaggle is a fantastic platform to apply your ML knowledge to real-world problems and datasets.
- It provides leaderboards, public kernels (code notebooks), and a collaborative environment to learn from the community.
- Start with beginner competitions like Titanic – Machine Learning from Disaster, and gradually move to advanced problems.
3. Read Research Papers and Blogs
- Stay updated with cutting-edge developments by reading research papers from arXiv or top conferences like NeurIPS, ICML, and CVPR.
- Follow ML-focused blogs such as Distill.pub, Towards Data Science, and blogs by Google AI and OpenAI.
- This helps you understand the latest trends, algorithms, and real-world applications.
4. Learn Math Basics
- Mathematics is the backbone of ML. Develop a good grasp of:
- Statistics: Probability, distributions, hypothesis testing, and regression.
- Linear Algebra: Vectors, matrices, eigenvalues, and matrix operations.
- Calculus: Derivatives, gradients, and optimization techniques.
- These concepts help you understand the theory behind ML algorithms and how they work under the hood.
5. Build a Portfolio of ML Projects
- Create GitHub repositories for your projects, including well-written READMEs and visualizations.
- Work on diverse domains like image classification, natural language processing, time series forecasting, and recommender systems.
- Having a strong portfolio improves your job prospects and demonstrates your hands-on expertise to potential employers.
By following these tips consistently, you'll build both your theoretical foundation and practical skills—essential for mastering machine learning and becoming a job-ready ML practitioner or data scientist.
| Read More: Machine Learning Engineer Roadmap 2025 |
Conclusion
Mastering machine learning requires consistent practice, curiosity, and a willingness to dive deep into both theory and hands-on projects. By leveraging the right tools, following structured workflows, and continuously learning from the community, you can build robust and scalable ML solutions that solve real-world problems.
Keep experimenting, stay updated with the latest research, contribute to open-source projects, and most importantly never stop learning. Machine Learning is not just about algorithms; it's about asking the right questions and turning data into actionable insights. If you want to deep dive in ML and secure your future open door Data Science & Machine Learning Certification Training Program and make your dream achievable.
Happy Learning, and may your models always converge!
FAQs
Machine Learning is a subset of AI that enables systems to learn and improve from experience without being explicitly programmed.
- AI is the broader concept of machines simulating human intelligence.
- ML is a subset of AI focused on learning from data.
- Deep Learning is a subset of ML using neural networks with many layers.
A model is a mathematical representation trained on data to make predictions or decisions.