


10
JulModel Evaluation in Machine Learning
27 Jul 2025
Advanced
11.6K Views
6 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
Introduction
A key component of machine learning is model evaluation, which entails evaluating the efficiency and performance of a developed model. Its main goal is to evaluate if the model achieves the desired goals and how well it generalizes to new data. By assessing models, we can choose the best one out of several options and learn more about their limits.
The usage of data from testing and training is often involved in the evaluation process. A part of the available data is used during training to instruct the model in pattern recognition and prediction. However, a different set of data that wasn't utilized during training must be used to test the model in order to assess its performance. This makes sure that the performance of the model is evaluated using hypothetical instances that simulate real-world situations.
The quantification of the model's performance through performance metrics makes them crucial for model evaluation. The metrics selected depend on the particular issue being resolved. Metrics like recall, recall accuracy, recall precision, F1 score, & AUC-ROC are frequently employed for classification tasks. Precision and recall assess the model's capacity to accurately identify examples that are positive, while accuracy assesses the percentage of occurrences that are correctly categorized. The F1 score combines recall and precision into one statistic. The model's ability to distinguish between both positive and negative occurrences across various thresholds is measured by AUC-ROC.
Mean squared error (MSE) and mean absolute error (MAE), which calculate the average squared variance between predicted and actual values, are two common performance metrics for regression tasks. Another often-used statistic, R-squared, shows the percentage of the target variable's variance that the model accounts for.
To provide a more reliable evaluation of a model's performance, cross-validation is a technique that is frequently used in model evaluation. It involves performing testing and training iterations after dividing the data into numerous subgroups, or folds. This reduces dependence on one train-test split and helps in generating a more accurate evaluation of the model's performance.
Model Evaluation in Machine Learning
Model Evaluation in Machine Learning is the process of determining a trained model's effectiveness and quality using a variety of metrics and approaches. It entails evaluating whether the model achieves the required goals and how well it generalizes to fresh, untested data. We are able to examine several models, grasp their advantages and disadvantages, and make informed judgments thanks to model evaluation. Determining the model's predicted accuracy and evaluating its effectiveness in solving the given problem are the key goals of model evaluation.
The testing and evaluation set, which was not utilized throughout the model's training phase, is necessary in order to evaluate a model. This guarantees that the model is evaluated using hypothetical cases, giving a more accurate indication of how well it performs. The assessment set should ideally reflect the kind of data the model will encounter in the real world.
Model evaluation techniques in machine learning
In machine learning, a variety of strategies are employed for model evaluation. These methods aid in evaluating the functionality and generalizability of trained models. Typical model evaluation techniques in machine learning include:
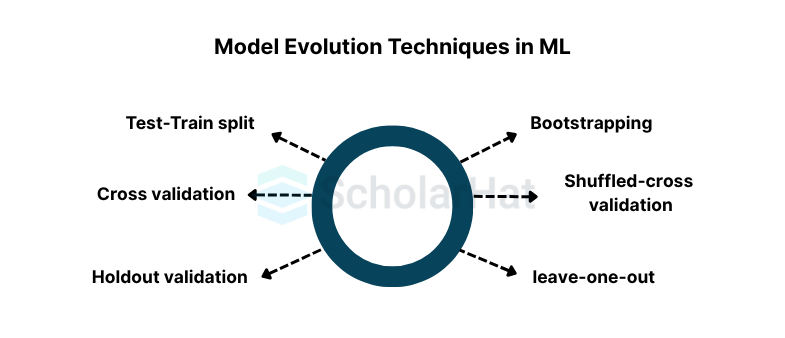
- Test-Train Split: The training set and testing set are separated from the available dataset in this method. The training set is used to develop the model, and the testing set is used to assess it. The performance of the model on the testing set is used to calculate evaluation measures like accuracy and mean squared error. This method offers a quick and easy way to assess the performance of the model, but it could be sensitive to how the data are split.
- Cross-Validation: Cross-validation addresses the drawback of a single train-test split and is a more reliable technique. It entails partitioning the dataset into several folds or subgroups. The model is tested on the last fold after being trained on a variety of folds. Each fold serves as the assessment set as this process is done numerous times. The performance of the model is then estimated more accurately by averaging the evaluation metrics across iterations. K-fold cross-validation, stratified cross-validation with k-folds, & leave-one-out cross-validation are examples of common cross-validation techniques.
- Holdout Validation: Similarly, to the train-test split, holdout validation entails reserving a unique validating set-in addition to the training & testing sets. The training set is used to develop the model, the validation set to fine-tune it, and the testing set to assess it. This method aids in picking the top-performing model and fine-tuning the model's hyperparameters.
- Bootstrapping: A bootstrapping process is a revising approach that entails randomly sampling replacement data from the original dataset in order to produce numerous datasets. A model is trained and evaluated using each bootstrap sample, and the performance of the model is estimated using an aggregate of the evaluation results. A measure of the model's reliability & robustness can be obtained by bootstrapping.
- Shuffled Cross-Validation: This method extends k-fold cross-validation by randomly shuffling the data before the cross-validation step. It helps to minimize any potential bias induced by the ordering of the data by ensuring that the data distribution is more evenly represented across the folds.
- Leave-One-Out: Leave-One-Out (LOO) is a specific instance of cross-validation in which the model is trained using the remaining data points while each data point is utilized as the evaluation set. The performance of the model is impartially estimated by LOO, but it might be computationally costly for large datasets.
Summary
Model evaluation, an important component of machine learning, includes evaluating the efficiency and performance of developed models. It seeks to ascertain how well models achieve the required goals and generalize to new data. A separate training dataset is usually used for training the model, while a separate testing dataset is often used for evaluation. In contrast to the popularity of mean squared error, mean absolute error, as well as R-squared for regression tasks, performance metrics including accuracy, recall, F1 score, precision, and AUC-ROC, are frequently employed for classification tasks.
Several methods are used to get a trustworthy evaluation. The data is separated into sets for training and testing using the train-test method. For iterative training and evaluation, cross-validation divides the data into several folds. For hyperparameter adjustment, holdout validation reserves a different validation set. Resampling is used in bootstrapping to build several datasets for aggregate performance estimates. Data distribution across folds is balanced via cross-validation using shuffle. Using the remaining data as training, Leave-One-Out analyses each data point separately. These methods offer many ways to evaluate the effectiveness and resilience of models.