

25
JunSupervised Learning
27 Jul 2025
Beginner
5.01K Views
10 min read

Learn with an interactive course and practical hands-on labs
Data Science with Python Certification Course
Supervised Learning
Introduction
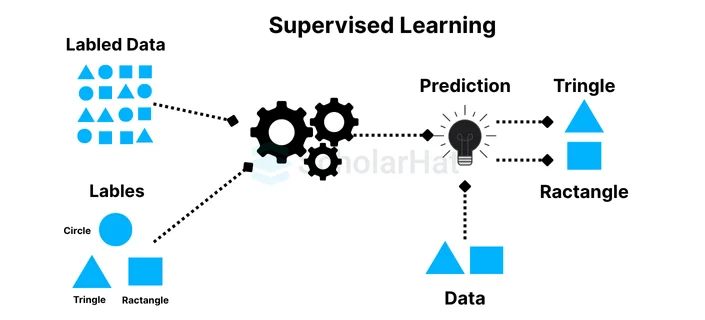
Machine learning, which tries to teach computers how to make precise predictions or judgments based on labeled examples, is built on the fundamental idea of supervised learning. It is one of the most popular learning paradigms and is utilized in a variety of fields, including recommendation systems, image recognition, and natural language processing.
In supervised learning, input data and associated output labels or target values are combined into a training dataset that is sent to the learning algorithm. The input data, sometimes referred to as features or attributes, reflect the details or parameters of the current issue. The desired or accurate output corresponding to the provided input is represented by the output labels or target values.
The objective of supervised learning is to develop a model or function that generalizes from the practice data to produce precise predictions or judgments on fresh, unexplored data. A mathematical function that transfers the input features to the output labels often serves as the model's representation. The algorithm learns this mapping through a process known as training when it iteratively modifies the model's parameters in accordance with the supplied labeled instances.
The approach works to reduce the discrepancy between the projected output and the actual output labels during the training phase. This is accomplished by applying the proper loss and error function, which measures how different the predicted and actual values are from one another. The approach updates the model's parameters & lowers the loss function using optimization strategies like gradient descent.
Once the model has been trained, the learned mapping function can be utilized to use the model to predict or decide on fresh, unobserved data. The model generates the anticipated output in accordance with the input characteristics of the new data. According to the nature of the issue, assessment measures like precision, recall, accuracy, or mean square error may be used to assess the predictions' correctness by contrasting them with the actual output labels.
A strong foundation for tackling a variety of predicting and making choices challenges is provided by supervised learning. Machines can learn from prior information and generalize it to generate predictions about upcoming, unknown data by utilizing labeled instances. This has important ramifications in many industries, including those that depend on accurate predictions and well-informed judgments, such as healthcare, banking, autonomous driving, & many more.
How Supervised Learning Works?
The ultimate objective of supervised learning is to build a model that correctly determines the output labels for a novel, unobserved input. The model may use current information to make wise decisions and working of supervised learning like picture classification, sentiment evaluation, fraud detection, & much more by learning from labeled instances. A machine learning algorithm is trained through supervised learning to generate precise predictions or judgments based on labeled samples. There are various steps in the procedure of working of supervised learning:
- Gathering of Data: Creating a dataset with input features & the appropriate output labels comes first. The dataset ought to be indicative of the issue you're trying to resolve.
- Data preprocessing: After a dataset has been gathered, it frequently needs to go through preprocessing stages to clean it up and modify it. Taking care of missing data, eliminating outliers, scaling or normalizing the features, and converting categorical variables to a numerical representation may all be necessary.
- Splitting Up the Data: The training set & the test set are often divided into two parts of the dataset. The model is trained using the training set, and its performance is assessed using the test set. This test of the model using hypothetical data aids in determining its generalizability.
- Selecting a Model: In order to learn from the data, you must choose an appropriate model and algorithm based on the task at hand. The kind of data, the difficulty of the issue, and the desired result all play a role in the model selection process. Decision tree models, support vector machines, random forest models, and neural networks are a few examples of well-known supervised learning algorithms.
- Model Training: This step of the training procedure involves feeding the selected model the training set. By changing its internal parameters repeatedly, the model develops the ability to map the input features to the matching output labels. Utilizing the right loss function, the goal is to reduce the discrepancy between the true labels and the anticipated outputs.
- Model Evaluation: The model is assessed on the test set after training in order to gauge its performance. Depending on the issue, other evaluation metrics, such as accuracy, precision, recall, F1 score, and mean squared error, might be utilized. The evaluation reveals the model's strengths and limitations and aids in determining how well it generalizes to new data.
- Model Deployment: If the model exhibits good performance on the test set, it may be used to make forecasts or judgments based on brand-new, untainted data. The learned mapping function is applied to the input features of the new data by the model, which then generates the anticipated result.
- Model Improvement: Because supervised learning is an iterative process, the model's performance may benefit from more iterations. To do this, one may need to tweak hyperparameters (parameters that govern the learning process), gather more labeled data, or test out various methods or model designs.
Types of Supervised Learning
In machine learning, there are various supervised learning algorithm types. The types of supervised learning consist of:
Classification
Based on the input features, classification is a type of supervised learning whose objective is to predict discrete class categories or labels for new instances. From the training data, the algorithm learns a decision boundary and a mapping function that gives each input instance the appropriate class label. Decision trees, logistic regression, support vector machines (SVM), and k-nearest neighbors (KNN) are examples of common classification techniques.
Regression
A supervised learning method known as regression works with forecasting continuous numerical values and quantities. From the properties of the input variable to the constant output variable, the algorithm learns a mapping function. In order to make predictions on new data, regression algorithms seek to identify the relationship between the input variables & the output variable. Random forests, polynomial regression, and linear regression are a few examples of regression methods.
Ordinal Regression
When the output variable has ordered or ranked categories, ordinal regression, a specific type of supervised learning, is utilized. Instead of predicting the exact values of the categories, it seeks to forecast their relative order or rank. When the output variables have a natural ordering, such as rating systems or customer satisfaction levels, this form of learning is beneficial.
Multi-label Classification
A supervised learning task that allows each instance to be connected to a variety of class labels is known as multi-label classification. Predicting the set of labels that are pertinent for each instance is the objective. In systems that allow for the assignment of numerous labels to a single instance, such as text categorization, image tagging, & recommendation engines, it is frequently utilized.
Series Labelling
Sequence labeling is a form of supervised learning in which each piece of a series of data is given a label. Tasks like named entity recognition in natural language processing, where every word in a sentence is labeled with its appropriate entity type, fall under this category.
Abnormalities Detection
Also referred to as outlier detection, anomaly detection is a subset of supervised learning which focuses on locating rare or out-of-the-ordinary occurrences in a dataset. The system learns to distinguish between typical and anomalous events after being trained on a dataset that is largely normal. It is frequently used in industrial systems for failure, fraud, and network intrusion detection.
Supervised Machine Learning Algorithms
There are several supervised machine learning algorithms available, each with unique advantages, disadvantages, and use cases. Some well-liked supervised learning algorithms are listed below:
- Linear Regression: For jobs requiring regression, linear regression is a straightforward and popular approach. Applying a linear equation to the data, it describes the link between the input features and the continuous output variable.
- Logistic Regression: For binary classification tasks, logistic regression is a classification algorithm. Using a logistic function, it calculates the likelihood that a certain instance will fall into a certain class.
- Decision Trees: Decision trees are flexible algorithms that can be applied to both regression and classification tasks. On the basis of the input features, they divide the feature space into zones and produce predictions based on the dominant class or average value of the occurrences inside each region.
- Random Forests: Random forests are a decision tree-based ensemble learning technique. Each tree within the forest is trained using a different random subset of the data, & predictions are then made by averaging or consulting the opinions of the various trees. The robustness and versatility of random forests in handling large, complicated datasets are well known.
- Support Vector Machines (SVM): This effective approach can be used for both classification and regression tasks. It locates an ideal hyperplane that, while minimizing mistakes, maximizes the margin between various classes or best fits the data. SVM uses many kernel functions to handle both linear and non-linear issues.
- Naive Bayes: Bayes' theorem is the foundation of the probabilistic classifier known as Naive Bayes. Given the class title, it is assumed that the input features are independent of one another. Naive Bayes can be useful and efficient in many real-world situations despite its imprecise premises.
- K-Nearest Neighbors (KNN): K-nearest-neighbors (KNN) is a non-parametric technique used for both regression and classification tasks. Based on the majority vote or average value of an instance's k nearest neighbors in the feature space, it assigns the class or forecasts the value of the instance.
- Gradient Boosting Machines (GBM): GBM is an approach to ensemble learning that sequentially pairs weak learners, usually decision trees. Iteratively adding new trees, each of which fixes the flaws of the preceding ones, is how the model is constructed. GBM algorithms with strong predictive performance include XGBoost and LightGBM.
- Neural Networks: Based on the structure & operation of the human brain, neural networks are a potent class of algorithms. They are made up of layered networks of interconnected nodes (neurons). Neural networks are frequently employed in a variety of applications, including speech recognition, natural language processing, and picture and pattern identification because they can handle complicated patterns and relationships in the data.
Summary:
Machine learning is built on the fundamental idea of supervised learning, which is teaching computers to make precise predictions or judgments using labeled examples. It uses a training dataset made up of input features & labels for related outputs. The objective is to develop a function or model that can generalize from the training data to make reliable assumptions about the novel, unobserved data. Data must be gathered, preprocessed, divided into training and test sets, a suitable model selected, trained by minimizing the difference between true and predicted values, evaluated for performance, deployed for predictions, and iteratively improved as necessary.
Supervised machine learning algorithms come in a variety of forms. Types of Supervised Learning forecast continuous numerical results, whereas classification algorithms forecast discrete class labels. Ordinal regression deals with ordered categories, multi-label classification labels examples with multiple labels, sequence labeling labels elements in a sequence, and anomaly detection pinpoints instances that are out of the ordinary. Several well-liked supervised learning techniques are decision trees, random forests, support vector machines, naive Bayes, gradient boosting machines, neural networks, linear regression, logistic regression, and k-nearest neighbors. Each algorithm has unique traits and is suitable for a variety of problems.
Applications for supervised learning are numerous in many industries, including autonomous vehicles, banking, and healthcare. Significant improvements in a variety of fields have resulted from the ability of machines to learn from labeled examples, generalize information, and make reliable predictions or choices.