








27
JunKafka Microservices: Step-by-Step Implementation Guide
23 Sep 2025
Beginner
4.31K Views
18 min read

Learn with an interactive course and practical hands-on labs
Free .NET Microservices Online Course - Beginners Start Here
Kafka Microservices is a modern approach for building scalable, event-driven applications by combining the power of Apache Kafka with microservices architecture. This setup allows different services to communicate with each other asynchronously, reducing tight coupling and improving system resilience.
In this microservices tutorial, you will able to learn about Apache Kafka, kafka architecture, core components of kafka architecture, kafka in microservices architecture, how to implement kafka in microservices and more on. Prepare for high-paying developer roles with salaries up to ₹12–20 LPA — all 100% free with our Free .NET Microservices Course.
What is Apache Kafka?
Apache Kafka is a distributed streaming platform designed to handle large-scale, real-time data processing.
- It operates as a publish-subscribe messaging system, allowing applications to send, store, and process streams of data (events) efficiently.
- It was first created at LinkedIn, but now many people use Kafka to create data paths, systems that respond to events, and to analyze data as it happens.

Kafka Architecture:
Kafka architecture is the blueprint of how Apache Kafka works internally to handle massive streams of data in real time. It defines the components, their responsibilities, and how they interact to enable publish-subscribe messaging, fault tolerance, and horizontal scalability.
Kafka plays the role of a backbone in microservice architecture, enabling reliable event-driven communication, reducing service dependencies, and improving overall system performance and resilience.
Components of Kafka Architecture
The Core Components of Kafka microservices are:
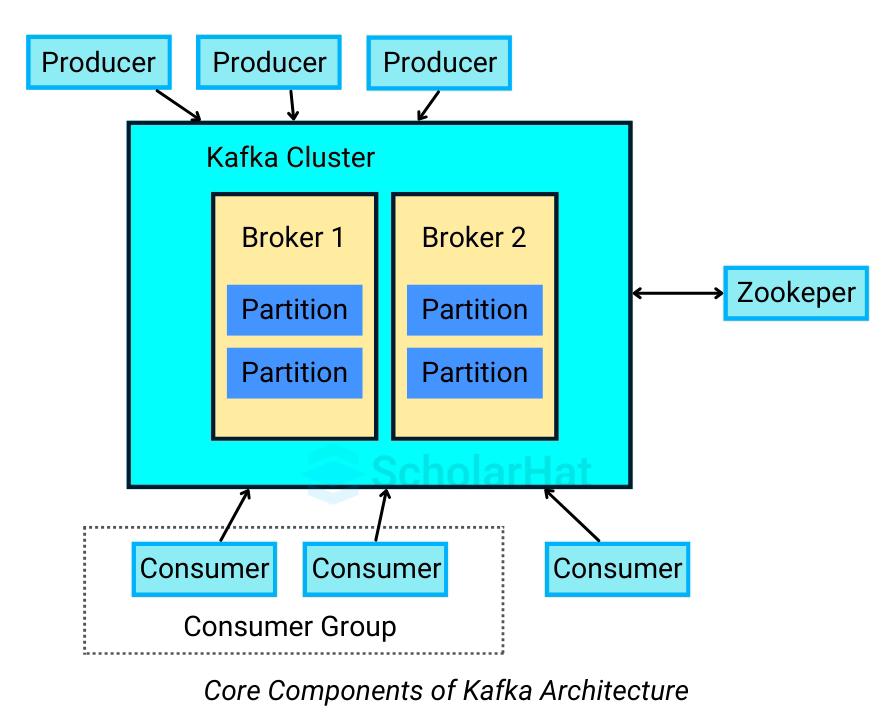
- Kafka Cluster: A Kafka cluster is a distributed system composed of multiple Kafka brokers working together to handle the storage and processing of real-time streaming data.
- Broker: A Kafka server that stores and manages data, forming a cluster with other brokers to distribute partitions and ensure scalability.
- Topic: A logical channel for organizing messages, split into partitions for parallel processing (e.g., order-events for order data).
- Partition: A subset of a topic’s data, stored as an ordered log on a broker, enabling parallel reads and writes by consumers.
- Producer/Consumer: Producers send messages to topics, while consumers subscribe to topics to process messages, supporting event-driven workflows.
- Consumer Group: A group of consumers that share message processing load, with each partition assigned to one consumer for balanced scalability.
- ZooKeeper: ZooKeeper manages cluster metadata, coordinates brokers, and handles leader election for partitions.
Kafka in the Microservice Architecture
Microservices architecture is a design pattern where an application is broken down into smaller, self-contained, independent services that communicate with each other. While this improves scalability and flexibility, it also introduces challenges in communication, data consistency, and fault tolerance, especially when many services need to interact in real time.
To overcome these challenges, Apache Kafka comes into play. Kafka acts as a central event hub that enables asynchronous, decoupled communication between microservices. Instead of calling each other directly, services publish events to Kafka topics and other services subscribe to those topics to react to events as they occur.
Benefits of Using Kafka in Microservices Architecture
Apache Kafka is a natural fit for microservice-based systems because it provides scalable, fault-tolerant, and decoupled communication. Here are the main benefits:
1. Loose Coupling Between Services
- Kafka decouples producers and consumers, allowing services to work independently without knowing each other’s existence.
- This makes adding, removing, or updating services seamless without breaking the communication flow.
2. Scalability
- Kafka’s partition-based architecture lets you scale both message throughput and consumer processing horizontally.
- As the system grows, you can simply add more partitions or consumers to handle increased load.
3. Reliability & Fault Tolerance
- Kafka replicates messages across multiple brokers, ensuring zero data loss even if a node fails.
- Messages are stored until they are successfully consumed, so no service misses critical data.
4. High Performance
- Kafka is optimized for high throughput and low latency, processing millions of messages per second.
- This makes it ideal for real-time applications like payments, inventory tracking, and IoT systems.
5. Asynchronous & Event-Driven Communication
- Producers publish events without waiting for consumer responses, improving system responsiveness.
- This allows services to react automatically to events, supporting true event-driven workflows.
6. Data Replay & Event Sourcing
- Kafka retains messages for a configurable period, allowing consumers to reprocess past events anytime.
- This feature is essential for debugging, analytics, or rebuilding state after service downtime
How to Implement Kafka Microservices: Step-by-Step Guide
Implementing Apache Kafka in a microservices architecture allows services to communicate asynchronously and reliably.
Step 1:Install and Setup the Kafka
1. Download & Install Kafka
- Download Apache Kafka:kafka.apache.org
- Extract the files and navigate to the Kafka directory.
2. Start Zookeeper & Kafka Broker:
Only Required for Kafka versions below 3.3. Newer versions support KRaft mode and don’t need Zookeeper separately
bash
# Start Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# Start Kafka Broker
bin/kafka-server-start.sh config/server.propertiesVerify Installation:
- Use bin/kafka-topics.sh --list --bootstrap-server localhost:9092 to ensure Kafka is running.
Step 2: Create a Kafka Topic
Topics are logical channels where messages are published and consumed.
bashbin/kafka-topics.sh --create \
--topic order-events \
--bootstrap-server localhost:9092 \
--partitions 3 \
--replication-factor 1
- Topic Name: order-events
- Partitions: Help scale consumers by parallelizing message processing.
- Replication Factor: Ensures data is not lost if a broker fails.
Step 3: Set Up Spring Boot Project
For a Spring Boot microservice:
Add required dependencies in pom.xml:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>- For Node.js, use kafkajs or node-rdkafka.
- For Python, use confluent-kafka-python.
- This step depends on your tech stack, but the concept is the same.
Step 4: Configure Kafka in Your Application
Configure the Kafka server address, serializers, and consumer group in: application.yml (Spring Boot example):
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: order-service-group
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
This ensures your app knows where Kafka is and how to handle messages.
Step 5: Implement the Producer Service
Producer publishes events to Kafka whenever a relevant business action occurs.
Example (Spring Boot Java):
@Service
public class OrderProducer {
private final KafkaTemplate kafkaTemplate;
public OrderProducer(KafkaTemplate kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void publishOrder(String orderJson) {
kafkaTemplate.send("order-events", orderJson);
System.out.println("✅ Order event published: " + orderJson);
}
}
This publishes a message to the order-events topic.
Step 6: Implement the Consumer Service
Consumer listens to events and performs appropriate actions.
Example (Spring Boot Java):
@Service
@KafkaListener(topics = "order-events", groupId = "inventory-service-group")
public class InventoryConsumer {
public void consume(String message) {
System.out.println(" Received order event: " + message);
// Update inventory or trigger further actions
}
}
When a new message is published, this consumer will process it automatically.
Step 7: Integrate with Business Logic
- Trigger the producer when an event occurs (e.g., order placed, payment confirmed).
- Attach consumers to services that need to respond (e.g., inventory updates, notifications).
- This ensures services stay decoupled while still reacting to each other’s events.
Step 8: Handle Failures Gracefully
Fault tolerance is crucial in production.
- Dead Letter Topics: Store messages that fail after multiple retries.
- Retry Mechanisms: Implement exponential backoff before re-processing.
- Logging & Monitoring: Use tools like ELK Stack or Prometheus to track errors.
This prevents message loss and allows debugging without impacting live traffic.
Step 9: Test End-to-End
- Unit Test: Verify producers send events and consumers receive them.
- Integration Test: Run Kafka locally (Testcontainers is great for CI/CD pipelines).
- Failure Simulation: Stop a consumer and ensure messages are reprocessed when it restarts.
Step 10: Deploy & Monitor in Production
- Deployment: Run Kafka on-premises, or use managed services like AWS MSK, Confluent Cloud, Azure Event Hubs for Kafka API.
- Monitoring: Track consumer lag, broker health, and topic throughput.
- Scaling: Add partitions or consumers to handle increased traffic.
A properly monitored Kafka setup guarantees smooth communication in production.
Emerging Trends: Kafka Microservices
Kafka is no longer just a messaging system — it’s becoming the backbone of modern, event-driven architectures. Here are the key trends shaping the future of Kafka in microservices:
1. Fully Managed & Serverless Kafka
- No Cluster Management: Platforms like AWS MSK and Confluent Cloud handle provisioning, scaling, and upgrades automatically.
- Focus on Business Logic: Developers can build and deploy event-driven microservices without worrying about infrastructure.
2. Real-Time Stream Processing as Default
- Always-On Analytics: Kafka Streams, Flink, and ksqlDB power real-time insights for fraud detection, personalization, and monitoring.
- Eliminating Batch Jobs: Continuous event processing reduces latency and replaces traditional batch ETL pipelines.
3. Global-Scale Deployments with Multi-Cluster Architecture
- Geo-Replication: MirrorMaker 2.0 and Cluster Linking keep data synchronized across regions for disaster recovery.
- Low-Latency Global Apps: Users get faster responses thanks to local data availability near their region.
4. Standardization with AsyncAPI & Event Contracts
- Clear Event Documentation: AsyncAPI ensures consistent definitions for topics, schemas, and message payloads.
- Fewer Breaking Changes: Event contracts reduce miscommunication between teams and prevent integration failures.
5. Security & Governance Automation
- Automated ACL & Schema Checks: Improves compliance with regulations like GDPR and SOC 2.
- Centralized Policy Enforcement: Ensures consistent security across all microservices and teams.
Real-World Example of Kafka Microservices
Netflix
- Netflix uses Netflix uses Kafka to stream billions of events per day for monitoring, recommendations, and real-time analytics.
- Kafka enables personalized recommendations, near real-time A/B testing, and rapid troubleshooting to deliver a seamless viewing experience for millions of users.
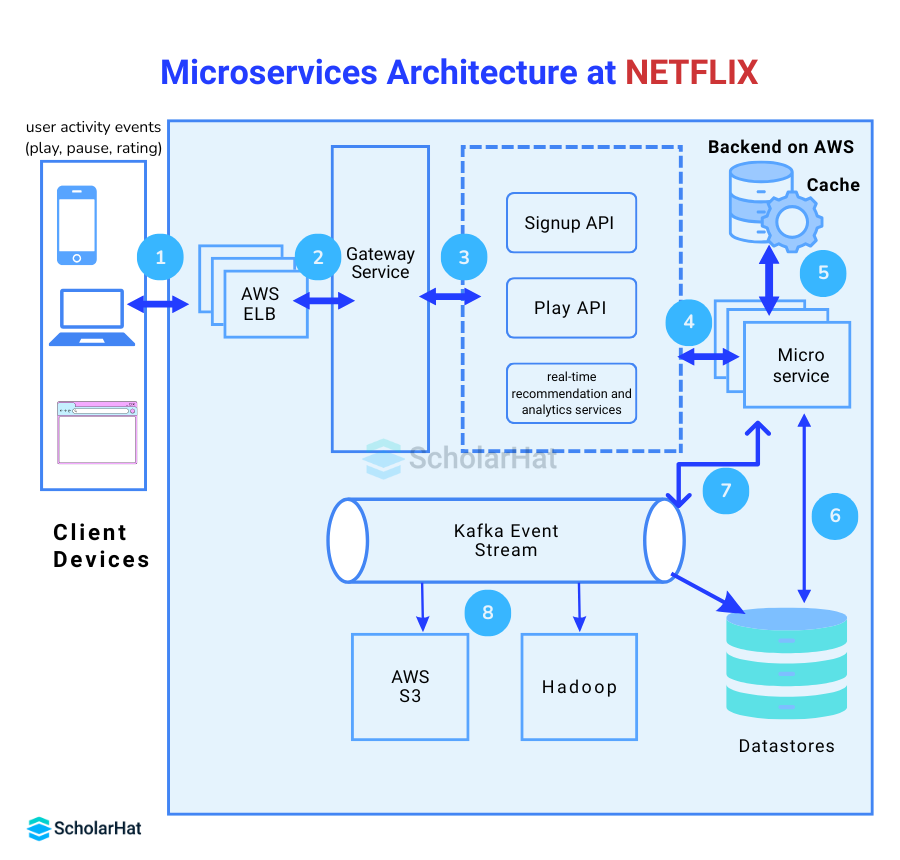
Explanation of Kafka in Microservices Architecture at Netflix
1. Client Devices Trigger Events
- Netflix users interact with the platform through multiple devices (mobile, web, smart TV).
- Events like Play, Pause, Stop, Rate, Search are generated and sent to the backend.
2. Load Balancing & Gateway Service
- AWS ELB (Elastic Load Balancer) distributes incoming traffic from millions of users across multiple Netflix backend servers.
- Gateway Service acts as an entry point for client requests and routes them to appropriate microservices (like Signup API, Play API).
3. API Calls & Microservices
- Once requests pass through the gateway, they hit specific APIs: Signup API for user registration, Play API for streaming requests
- These APIs are implemented as independent microservices, allowing Netflix to scale, update, or fix issues without affecting other services.
4. Backend & Caching
- Microservices interact with databases and caching layers to quickly fetch user data (watch history, preferences, etc.).
- Caching is critical for reducing latency in a high-traffic system like Netflix.
5. Datastores & Event Generation
- Each interaction (play, pause, rating) generates an event.
- These events are written into Kafka Event Stream – a highly scalable, distributed messaging system that Netflix uses for real-time event processing.
6. Kafka Event Stream
- Kafka acts as a central data pipeline, streaming all events (millions per second).
7. Real-Time Recommendations & Analytics
- Based on Kafka event streams, Netflix provides personalized recommendations instantly.
- Analytics teams use this event data for: Improving recommendation algorithms, identifying trending shows and detecting performance issues
Best Practices for Kafka Microservices
Best practices is crucial for maintaining data consistency, performance, and fault tolerance in Kafka microservices
1. Design Topics & Partitions Smartly: Use clear, descriptive topic names (e.g., order-events, user-signups) and plan partitions for scalability and parallelism from the start.
2. Ensure Idempotent Producers & Consumers: Enable idempotent producers and make consumer logic idempotent so duplicate messages do not cause inconsistent states.
3. Monitor Consumer Lag & Throughput: Track consumer lag continuously, set alerts for high lag, and scale consumers or partitions when needed to avoid bottlenecks.
4. Use Schema Registry for Data Compatibility: Maintain consistent event formats with Avro/JSON Schema/Protobuf and enforce backward compatibility to avoid breaking consumers.
5. Implement Error Handling & Dead Letter Queues (DLQ): Retry failed messages with backoff and send persistent failures to a DLQ for manual inspection and recovery.
Ready to build fault-tolerant Java apps? Start your certification journey in microservices with our Java Microservices Course now.
Conclusion
Kafka has become the backbone of modern microservices architecture, enabling real-time communication, scalability, and fault tolerance at a global scale. Kafka isn’t just a message broker; it’s the central nervous system of microservices, helping businesses react faster, deliver seamless experiences, and unlock the full potential of real-time data.
Build and deploy .NET microservices like a pro. Enroll in our .Net Microservices Training to enhance your skills and earn credentials that open doors to senior .NET positions.
FAQs
Apache Kafka is a distributed event streaming platform used to decouple microservices and enable asynchronous communication. It helps services exchange events reliably and at scale, improving fault tolerance and system responsiveness.
Instead of direct service-to-service calls, Kafka allows microservices to publish and subscribe to events via topics, which reduces tight coupling, improves scalability, and allows independent deployment of services.
Kafka communication is asynchronous, producers write events to topics, and consumers read them at their own pace, which prevents bottlenecks and handles traffic spikes gracefully.
Yes, Kafka provides durability and fault tolerance through message replication across brokers. When properly configured (acks=all, replication factor ≥ 3), data loss risk is minimal even if brokers fail.
Yes, Apache Kafka is open source and free. However, running and managing a Kafka cluster at scale may require infrastructure and operational costs unless you use a managed service like AWS MSK or Confluent Cloud.
Take our Microservices skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.