






25
JunDelete Duplicate Rows in SQL Server From a Table
18 Sep 2025
Intermediate
366K Views
5 min read

Learn with an interactive course and practical hands-on labs
Free SQL Server Online Course with Certificate - Start Today
Delete Duplicate Rows in SQL Server From a Table: An Overview
Even if a table has a UniqueID Column with identity, there may be occasions when it is necessary to eliminate duplicate records. In this article, I'll explain the best way to delete duplicate rows in SQL Server from a table.
SQL Server skills can boost your earning potential by 22% in the next 3 years. Enroll in our Free SQL Server Course with Certificate today!
Read More - Most Asked DBMS Interview Questions
What is Deleting Duplicate Rows in SQL?
Duplicate records in a SQL Server table might cause major issues. Duplicate data can lead to multiple order processing, inaccurate reporting results, and other issues. Depending on the situation, SQL Server provides a variety of ways for dealing with duplicate records in a table. They are:
- Unique constraints in Table
- No Unique constraints in Table
1. Unique Constraints in Table
Delete duplicate rows in SQL states that a table having a unique index can use the index to find duplicate records, which can subsequently be deleted. Self-joins, ranking the data by the maximum value, using the RANK function, or NOT IN logic are used for identification.
2. No Unique Constraints in Table
Without a particular index, deleting duplicate entries in SQL can be challenging due to the lack of unique constraints in the table. The ROW NUMBER() method can be used in conjunction with a common table expression (CTE) to sort data and subsequently delete duplicates.
Example of Deleting Duplicate Rows in SQL Server from Table
Suppose we have the below Employee table in SQL Server.
CREATE TABLE dbo.Employee
(
EmpID int IDENTITY(1,1) NOT NULL,
Name varchar(55) NULL,
Salary decimal(10, 2) NULL,
Designation varchar(20) NULL
) This SQL script generates a table called "Employee" with fields for the employee ID (auto-incremented), name, salary, and designation. The table structure is defined using the proper data types and constraints.
The data in this table is as shown below:
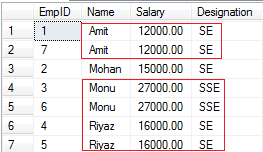
Read More - SQL Interview Questions And Answers For Freshers
Remove Duplicate Rows by using ROW_NUMBER()
In SQL Server, you can delete duplicate rows by using the ROW_NUMBER() function to assign a unique number to each row and then deleting rows with row numbers greater than 1, resulting in only one instance of each duplicate row.
WITH TempEmp (Name,duplicateRecCount)
AS
(
SELECT Name,ROW_NUMBER() OVER(PARTITION by Name, Salary ORDER BY Name)
AS duplicateRecCount
FROM dbo.Employee
)
--Now Delete Duplicate Rows
DELETE FROM TempEmp
WHERE duplicateRecCount > 1 This code generates a common table expression (CTE) called TempEmp, where each row is assigned a row number within the partitions indicated by Name and Salary. Then it deletes entries from TempEmp with a row count greater than one, essentially deleting duplicate rows from the original Employee table based on Name and Salary combinations.
--See affected table
Select * from Employee This code gets and shows all data from the "Employee" table, allowing you to see any changes, such as the removal of duplicate rows.
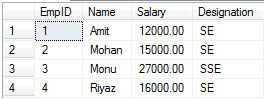
Read More:
Summary
In this article, I expose how can you remove duplicate rows from a table in SQL Server. I hope after reading this article you will be able to use these tips.
Full-Stack .NET Developers earn up to ₹35 LPA in India’s tech boom. Kickstart your high-paying career with our full stack .NET developer course today!
FAQs
- To begin, specify the range in which you want to eliminate duplicates. To select the full table, use Ctrl +A.
- Navigate to the Data tab > Data Tools group, then select the Remove Duplicates button.
- The Remove Duplicates dialogue box will appear; pick the columns to check for duplicates, then click OK.
In this case, we will use the Rank function, the "PARTITION BY" clause, and the "INNER JOIN." Similar to the CTE query, the above query "[rank]" column returns a unique row ID for each duplicate row. To eliminate duplicate records, also include a "Where" clause with the constraint "[rank] > 1".
To delete the duplicate record with SQL Server, we can use the SET ROWCOUNT command, which limits the number of rows affected by a query. By setting it to 1, we can simply delete one of these rows from the table.
To eliminate duplicate records, use "delete from names a where rowid > (select min(rowid) from names b where b.name=a.name and b.age=a.age);" after "SQL'".
Take our Sqlserver skill challenge to evaluate yourself!

In less than 5 minutes, with our skill challenge, you can identify your knowledge gaps and strengths in a given skill.